
در درسنامه ی قبل، لایه ی اول از شبکه های عصبی عمیق کانولوشن یعنی لایه ی کانولوشن را بررسی کردیم. در این قسمت، سایر لایه های این شبکه را مطالعه خواهیم کرد.
مقاله مرتبط :
-
- پیاده سازی شبکه عمیق در متلب: ساختن شبکه یادگیری عمیق ساده برای کلاسه بندی
- پیاده سازی شبکه عصبی عمیق در متلب – قسمت اول : کانولوشن
- پیاده سازی شبکه عصبی عمیق در متلب – قسمت دوم : پولینگ
- پیاده سازی شبکه عصبی عمیق در متلب – قسمت سوم : تماماً متصل
- پیاده سازی شبکه عصبی عمیق در متلب – قسمت چهارم : الگوریتم پس انتشار
پولینگ (Pooling) :
دومین لایه، لایه ی Pooling است. یک لایه Pooling معمولا بعد از یک لایه کانولوشن قرار می گیرد و از آن برای کاهش اندازه نقشه های ویژگی و پارامترهای شبکه می توان استفاده کرد. همانند لایه های کانولوشنی, لایه های Pooling بخاطر در نظر گرفتن پیکسل های همسایه در محاسبات خود, نسبت به تغییر مکان ( Translation ) بی تغییر ( با ثبات ) هستند. برای پیاده سازی این لایه دو روش رایج وجود دارد:
- Max pooling
- Average pooling
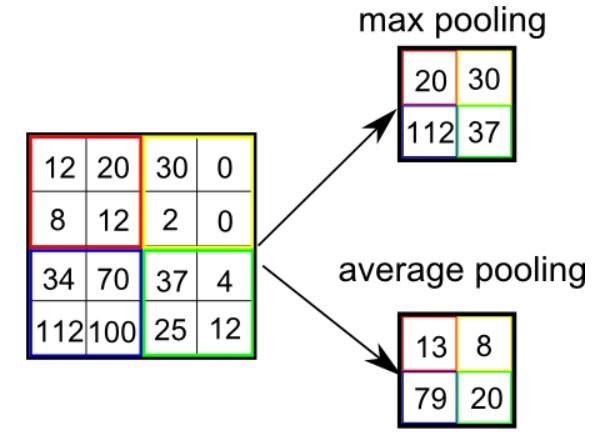
آنچه در این لایه اتفاق می افتد، کاهش ابعاد است. به این صورت که نقشه های ویژگی استخراج شده از لایه ی قبل، به پنجره های مجزا از هم ۲*۲ یا غیره تقسیم می شوند. بسته به نوع روش انتخاب شده، میانگین مقادیر موجود در هرکدام از پنجره ها ( Average pooling ) یا بیشترین مقدار موجود در این پنجره ( Max pooling ) محاسبه شده و به عنوان مقدار در نقشه ویژگی جدید انتخاب می شود.
درشکل زیر نحوه ی اعمال این دو روش نمایش داده شده است:
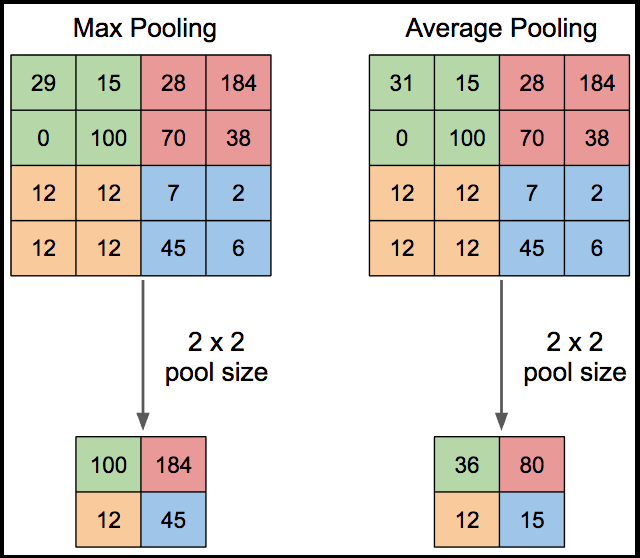
عموما از روش ماکس پولینگ استفاده می شود. در ادامه نحوه ی نوشتن کد ماکس پولینگ در محیط متلب آورده شده است.
<span style="color: #aeaeae; font-style: italic;">%Read an Example Image</span> x1 = <span style="color: #99cf50;">imread</span>(<span style="color: #65b042;">'child.jpg'</span>); x = <span style="color: #9b859d;">imresize</span>(x1, <span style="color: #3387cc;">1</span>); <span style="color: #aeaeae; font-style: italic;">% x = rgb2gray(x1);</span> <span style="color: #aeaeae; font-style: italic;">%convert to single format</span> x = <span style="color: #9b859d;">im2single</span>(x); <span style="color: #aeaeae; font-style: italic;">%Visualize the input x</span> <span style="color: #9b859d;">figure</span>(<span style="color: #3387cc;">1</span>); <span style="color: #9b859d;">clf</span>; <span style="color: #9b859d;">imagesc</span>(x); <span style="color: #aeaeae; font-style: italic;">%create a bank of linear filter</span> w = <span style="color: #e28964;">randn</span>(<span style="color: #3387cc;">5</span>, <span style="color: #3387cc;">5</span>, <span style="color: #3387cc;">3</span>, <span style="color: #3387cc;">10</span>, <span style="color: #65b042;">'single'</span>); <span style="color: #aeaeae; font-style: italic;">%convolution of the image with filters</span> <span style="color: #9b859d;">figure</span>(); <span style="color: #e28964;">for</span> k = <span style="color: #3387cc;">1 </span><span style="color: #e28964;">: </span><span style="color: #3387cc;">10</span> y(<span style="color: #e28964;">:</span>, <span style="color: #e28964;">:</span>, <span style="color: #e28964;">:</span>, k) = <span style="color: #e28964;">convn</span>(x(<span style="color: #e28964;">:</span>, <span style="color: #e28964;">:</span>, <span style="color: #e28964;">:</span>), w(<span style="color: #e28964;">:</span>, <span style="color: #e28964;">:</span>, <span style="color: #e28964;">:</span>, k), <span style="color: #65b042;">'valid'</span>); <span style="color: #9b859d;">subplot</span>(<span style="color: #3387cc;">2</span>, <span style="color: #3387cc;">5</span>, k); <span style="color: #9b859d;"> imshow</span>(y(<span style="color: #e28964;">:</span>, <span style="color: #e28964;">:</span>, k)) <span style="color: #e28964;">end</span>
Boureau et al تحلیل نظری دقیقی از کارایی Max pooling و Average pooling ارائه داد. Scherer et al هم مقایسه ای بین این دو عملیات انجام داد و فهمید Max pooling می تواند باعث همگرایی سریع تر , تعمیم بهتر ( بهبود تعمیم دهی ) و انتخاب ویژگی های نا متغیر بسیار عالی شود. طی سالهای اخیر پیاده سازی های سریع مختلفی از انواع مختلفی از CNN بر روی GPU انجام شده است که اکثر آنها از عملیات Max pooling استفاده می کنند .
لایه های Pooling از میان سه لایه شبکه های کانولوشن , تنها لایه ای هستند که بیشترین میزان مطالعه روی آنها انجام شده است. سه روش معروف در رابطه با این لایه وجود دارد که هرکدام اهداف متفاوتی را دنبال می کنند.
Stochastic pooling
یک کاستی Max pooling این است که نسبت به Overfitting مجموعه آموزشی حساس بوده، و تعمیم را سخت می کند. با هدف حل این مشکل, Zeiler et al روش Stochastic pooling را پیشنهاد داد که در آن عملیات قطعی Pooling با یک رویه اتفاقی جایگزین میشود. این رویه اتفاقی ,انتخاب تصادفی مقادیر در داخل هر ناحیه Pooling بر اساس یک توزیع چندجمله ای است. این عملیات شبیه Max pooling استاندارد با تعداد زیادی کپی از تصویر ورودی که هر کدام تغییرشکل محلی کوچکی دارند است. طبیعت تصادفی ( Stochastic ) بودن برای جلوگیری از مشکل Overfitting مفید بوده و به همین دلیل از آن در این روش استفاده شده است.
(Spatial pyramid pooling (SPP
معمولا روش های مبتنی بر شبکه های عصبی کانولوشن نیازمند یک تصویر ورودی با اندازه ثابت هستند. این محدودیت ممکن است باعث کاهش دقت تشخیص برای تصاویری با اندازه دلخواه شود. به منظور حذف این محدودیت , He et al از یک معماری شبکه عصبی کانولوشن معمولی استفاده کرد با این تفاوت که لایه Pooling آخر را با یک لایه Spatial pyramid pooling جایگزین نمود. این لایه قادر به استخراج نماد ها ( تصاویر ) با اندازه ثابت از تصاویر ( یا نواحی ) دلخواه است. این روش باعث ایجاد یک راه حل قابل انعطاف برای مدیریت مقیاس ها, اندازه ها و Aspect ratio های مختلف می شود که میتوان از آن در هر ساختار و معماری CNN ی استفاده کرده و کارایی آن را افزایش داد.
Def-pooling
مدیریت و رسیدگی به تغییر شکل یک چالش اساسی در بینایی کامپیوتر است. خصوصا در زمینه های مربوط به تشخیص اشیاء (Object recognition) . Max pooling و Average pooling برای مدیریت تغییر شکل ( Deformation ) مفید اند اما قادر به یادگیری محدودیت تغییر شکل ( Deformation ) و مدل هندسی اجزای شئ نیستند. به منظور مقابله بهتر با تغییر شکل Ouyang et al یک لایه Pooling جدید با تغییر شکل محدود ( Deformation constrained pooling layer ) معرفی کرد. که به Def-pooling layer معروف است. تا به این وسیله مدل عمیق ( Deep model ) بدست امده با یادگیری تغیرشکل الگوهای دیداری ( deformation of Visual patterns ) غنی شود. از این لایه می توان بجای لایه Max pooling در هر سطحی از انتزاع استفاده کرد.
می توان از ترکیب چندین نوع مختلف لایه Pooling که هر کدام با هدف و شیوه متفاوتی توسعه پیدا کرده اند, کارایی یک شبکه عصبی کانولوشن را افزایش داد.
در درسنامه های بعدی، مراحل دیگر فرآیند یادگیری عمیق را ادامه خواهیم داد.
بیشتر بخوانید :
- فرماندار اوکلند از پلاک خوان ها حمایت می کند اما مخالفان در اثربخشی آن تردید دارند
- لبنان استفاده از پلاک خوان های خودکار را تایید کرد
- چالش های مدیریت کلاس با ابزار جدید تشخیص چهره هوش مصنوعی
- آیا می توان از دوربین های ترافیکی برای گرفتن رانندگان الکلی استفاده کرد؟
- قانون پیشنهادی برای محدود کردن استفاده از پلاک خوان ها



