
شرکت ها در حال حاضر ، برای داشتن برآوردی از انگیزه مشتریان در برخورد با برند تجاری و یا محصولاتشان از تجزیه و تحلیل احساسات آن ها استفاده می کنند . شرکت ها با کند و کاو در توییت ها ، مصابحه ها و دیگر منابع به آسانی قادر خواهند بود تا احساسات مشتریان را از زبان طبیعی استخراج کنند . اما زمانی که کاربران آنلاین و در دسترس نیستند چه کار باید کرد؟
فروشندگان و نمایندگان مشتریان در مغازه ها می توانند ابراز احساسات مشتری را هنگامی که عصبانی و یا نا امید است مشاهده کنند ، اما به طور همزمان قادر نیستند تا در همه جا حضور داشته باشند . با این حال ، سال هاست که شرکت ها برای زیر نظر داشتن رفتار مشتریان از دوربین داخل مغازه ها استفاده می کنند .
به نظر می رسد شرکت ها به سبک اوروِلی ( Orwellian ) از این داده ها برای شناسایی موارد مهم در مغازه ها استفاده می کنند و بدون توجه به حریم شخصی ، راه مشتریان را دنبال و حتی به نگاه خاص آن ها ، توجه می کنند . بنابراین چرا احساسات را از دید خریداران نیز دنبال نکنیم؟
مسئله اصلی این است که ترجمه حرکات ۴۳ ماهیچه صورت به احساسات دشوار است . برای انسان ها آسان است زیرا ما سال ها تمرین داشته ایم ، اما رایانه ها ، جهان را به عنوان شبکه ای از اعداد که نشان دهنده مقادیر پیکسل است ، می بینند . ما قادر هستیم تا با نگاه به تصویر چهره شخصی به آسانی تفاوت بین لبخند و اخم را تشخیص دهیم ، اما این عمل برای یک مدل یادگیری ماشین بسیار مشکل خواهد بود .
برای حل این مشکل ، ما می خواهیم از یک شبکه عصبی عمیق کانولوشنی که در چارچوب یادگیری ماشین Keras اجرا شده است ، استفاده کنیم .
شبکه عصبی کانولوشنی ( CNN ) چیست؟
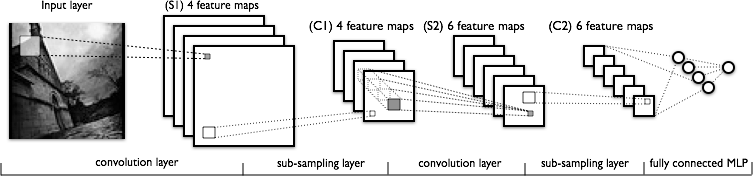
یک شبکه عصبی کانولوشنی ویژگی هایی از داده های دو بعدی را استخراج و به آن ها وزن اختصاص داده و در نهایت منجر به پیش بینی می شود . برای مثال ، اگر بخواهیم CNN را برای تشخیص اعداد دست نویس آموزش دهیم ، باید مجموعه داده ای از تصاویر ۱۰۰×۱۰۰ پیکسل این اعداد داشته باشیم .
CNN خطوط منحنی و مستقیمی در بخش های ۱۰×۱۰ پیکسلی را شناسایی می کند ، و بعد از تشخیص این ویژگی ها ، این مدل یاد می گیرد که ترکیبی از منحنی ها و خطوط مشخص نشانگر اعداد خاصی است . یک عدد منحنی به خصوص مانند ۸ از اعداد مستقیمی نظیر ۱ یا ۷ قابل تشخیص است . در مورد تشخیص احساسات چهره ، منحنی به طرف بالا که نشان دهنده ی لبخند است، می تواند با خوشحالی مرتبط باشد .
چرا یادگیری عمیق؟
در حال حاضر ، محققان از فاصله بین علائم صورت برای تشخیص احساسات استفاده می کنند . تصویر یک چهره نمایان گر موقعیت های اعضای صورت از قبیل دماغ ، چشم ها ، دهان ، گونه ، و دیگر فضا ها بوده و بنابراین فواصل میان این نقاط حساب شده ، و سپس آستانه هایی برای تشخیص احساسات ایجاد شده است . اگر چهره داخل تصویر در حال لبخند زدن باشد ، موقعیت گونه ها به چشم ها نزدیک تر ، دهان کشیده تر و چشم ها پیچ خورده تر می باشند .
این رویکرد در تنظیمات کنترل شده کارایی دارد ، اما اگر فقط بتوانیم نصف چهره را در عکس ببینیم چه ؟ اگر چهره کمی چرخیده باشد چه ؟ برای به دست آوردن نقاط دقیق چهره ، شما باید تصویر را به صورت مصنوعی جابجا کرده تا چهره در مرکز قرار گیرد و مستقیم به دوربین نگاه کند . با رویکر یادگیری عمیق ، مدل می تواند انعطاف پذیر باشد و ویژگی های صورت را شناسایی کنید بدون این که جهت دار بودن صورت برایتان مهم باشد . تمام آنچه نیاز دارید داده ها هستند .
جمع آوری داده ها
این مدل با استفاده از مجموعه داده های تصاویر Cohn-Kanada ، JAFFE و FER-2013 آموزش داده شده است . این تصاویر با احساسات خوشحال ، غمگین ، منزجر کننده ، عصبانی ، متعجب ، ترسیده و خنثی برچسب گذاری شده اند و برای نرمال سازی و آماده کردن آن ها برای آموزش ، همه آن ها را به مقیاس خاکستری و اندازه ی کوچک شده با مقیاس ۱۹۲×۱۹۲ پیکسل تبدیل و شدت پیکسل ها را بین مقادیر ۰ و ۱ نرمال سازی کردیم . سپس عکس ها را به آرایه های Numpy برای استفاده در آموزش ها تبدیل کردم . به دلیل این که تعداد تصاویر در زمینه احساسات عصبانی و منزجر کننده کافی نبود ، من این دو زمینه را با یکدیگر ادغام کردم تا در نهایت ۶ دسته بندی داشته باشیم .
ساخت مدل
Keras چارچوبی برای یادگیری عمیق است که در TensorFlow گوگل ساخته شده است . این برنامه این امکان را می دهد تا با بسته بندی کردن ساده لایه ها ، ساختن و آزمایش مدل های دلخواه به آسانی انجام گردد . آنچه صدها خط کد را در TensorFlow یا هزاران خط کد در Python را به همراه داشته باشد ، در Keras فقط با ۳۰ خط کد نویسی به طول می انجامد .
model = Sequential() model.add(Conv2D(32, (5, 5), padding='same', activation='relu', input_shape=(1, 192, 192))) model.add(Conv2D(32, (5, 5), padding='same', activation='relu')) model.add(Conv2D(32, (5, 5), padding='same', activation='relu')) model.add(MaxPooling2D(pool_size=(2,2))) model.add(Conv2D(64, (3, 3), padding='same', activation='relu')) model.add(Conv2D(64, (3, 3), padding='same', activation='relu')) model.add(Conv2D(64, (3, 3), padding='same', activation='relu')) model.add(MaxPooling2D(pool_size=(2,2))) model.add(Conv2D(128, (3, 3), padding='same', activation='relu')) model.add(Conv2D(128, (3, 3), padding='same', activation='relu')) model.add(Conv2D(128, (3, 3), padding='same', activation='relu')) model.add(MaxPooling2D(pool_size=(2,2))) model.add(Flatten()) model.add(Dense(128, activation='relu')) model.add(Dropout(.5)) model.add(Dense(6, activation='softmax'))
اجازه بدهید تا اتفاقی که در بالا افتاده است را تجزیه کنیم.
Conv2D
اولین لایه کانولوشنی یک تصویر ۱۹۲×۱۹۲ پیکسل را می بیند و به بخش های ۵×۵ پیکسلی از تصویر توجه می کند . این لایه دارای ۳۲ فیلتر است ، یعنی آن که ۳۲ الگوی مختلف وجود دارد که لایه در هر قسمت ۵×۵ پیکسلی آن ها را جستجو خواهد کرد . الگو ها با آموزش مدل از داده ها ، مشخص می شوند ، اما به طور معمول مانند این خواهند بود :

هر الگو دارای وزن خاصی است ، و این وزن ها همانطور که مدل از داده ها می آموزد، تنظیم می شوند . از آنجا که هر قسمت ۵×۵ تصویر درای 32 بازنمایی مختلف است ، این لایه ۱۸۸x188x32 است . شما متوجه خواهید شد که این لایه با ابعاد عکس اصلی هم خوانی ندارد (۱۹۲×۱۹۲) . دلیل این امر این است که قسمت های ۵×۵ با یک پنجره کشویی ایجاد می شوند و یک پیکسل را در یک مرتبه در سراسر تصویر منتقل می کنند .
MaxPooling2D
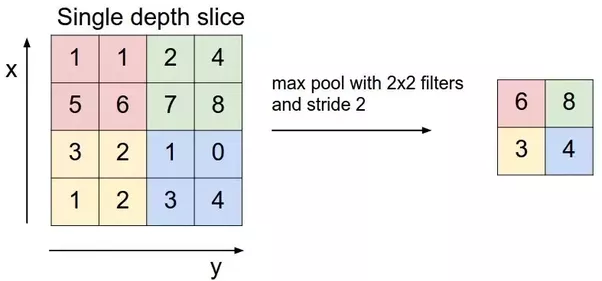
این یک لایه نمونه برداری است ، که حداکثر مقدار یک پنجره ۲×۲ را دریافت می کند . این لایه مانع از بیش برازش ( Overfitting ) مدل شده ، که برای پیش بینی احساسات بر روی تصویری که هرگز تا به الان ندیده است ، بسیار مهم است . هر قطعه با ابعاد ۱۸۸×۱۸۸ از لایه کانولوشنی ادغام ( Pooling ) شده اند و نتیجه آن ها در یک لایه با ابعاد ۹۴x94x32 جمع خواهد بود .
Flatten ، dense و Dropout
آخرین لایه ادغامی Flatten است و در لایه دیگر با عملکرد فعال سازی softmax استفاده می شود . این لایه ای است که کلاسه بندی احساسات را تولید می کند به همین دلیل برداری با ابعادی ۱×۶ خواهد بود . بیشترین مقدار بردار مربوط به یکی از احساس های شش گانه است : خوشحال ، غمگین ، ترسیده ، عصبانی ، متعجب ، یا خنثی . Dropout برای جلوگیری از بیش برازش مدل به داده ها استفاده می شود . Dropout با مقدار .۵ به این معنا است که از چرخه آموزش ، نیمی از نورون ها حذف می شوند ، بنابراین مدل قادر خواهد بود تا بهتر با تصاویر جدید تعمیم پیدا کند .
آموزش
برای آموزش مدل ، یک اسکریپت خودکارسازی ایجاد کردیم که “تجربه ها” را می گرفت و از آن ها مدلی می ساخت . سپسبا استفاده از تصاویر بزرگتر ، اضافه کردن لایه های کانولوشنی بیشتر ، افزایش و کاهش Dropout ، دیگر موارد را نیز آزمایش کردیم . نتایج آزمایش ها بر روی Github قابل مشاهده هستند .
آزمایش
بعد از ۱۵ دوره آموزش (که مدل تمام ۴۰۰۰۰ تصویر را ۱۵ بار مشاهده کرد) قادر بود تا در ۶۰% موارد یه درستی احساسات را شناسایی کند . این آزمایش بر روی تصاویری انجام شد که مدل هرگز پیش از این ندیده بود .
نتیجه
امیدواریم این راهنمای یادگیری عمیق کمتر از اصطلاحات و بیشتر از مفاهیم واضح استفاده کرده باشد تا بتوانید در کسب و کار خود استفاده کنید . اگر مایل هستید تا بیشتر و عمیق تر در این زمینه اطلاعات به دست آورید ، دوره جدید Andrew Ng را برای یادگیری عمیق بررسی کنید . می توانید از کد های موجود در صفحه Github این پروژه استفاده کنید . در آن جا مدل های آموزش دیده ای برای استفاده در CoreML برای iOS و TensorFlow Lite برای Android وجود دارد .
بیشتر بخوانید :
- پلاک خوان های شهر گرینزبوروی آمریکا فعلاً قرار نیست افزایش پیدا کنند
- فرماندار اوکلند از پلاک خوان ها حمایت می کند اما مخالفان در اثربخشی آن تردید دارند
- لبنان استفاده از پلاک خوان های خودکار را تایید کرد
- چالش های مدیریت کلاس با ابزار جدید تشخیص چهره هوش مصنوعی
- آیا می توان از دوربین های ترافیکی برای گرفتن رانندگان الکلی استفاده کرد؟



