
اگر از اصطلاح خوشه بندی در یادگیری ماشین، آگاهی داشته باشید، درک مفهوم مدل مخلوط گوسی ( Gaussian Mixture Model ) برای شما آسان تر خواهد بود. اگر در مورد خوشه بندی اطلاعاتی ندارید، می توانید از طریق مطلب خوشه بندی در یادگیری ماشین آن را فرا بگیرید. در این مقاله، ما تعریف GMM ، شرایط آن، پیاده سازی و در نهایت یک مطالعه کاربردی برای مدل مخلوط گوسی را مرور می کنیم. در آخر خواهید فهمید که چگونه GMM یک گسترش دهنده غیرمتعارف الگوریتم خوشه بندی است و چرا نسبت به بقیه، ترجیح داده می شوند.
GMM چیست؟
به منظور نشان دادن نماینده ای از یک زیرجمعیت توزیع شده نرمال، در کل جمعیت، ما از مدل مخلوط گوسی استفاده می کنیم. GMM، به داده هایی که زیرجمعیت ها به آن تعلق دارند، نیازی ندارد. این به مدل اجازه می دهد تا بطور خودکار، زیرجمعیت ها را یاد بگیرد. از آنجا که ما از وظایف زیرجمعیت آگاهی نداریم، این امر تحت یادگیری بدون نظارت قرار می گیرد.
برای مثال، فرض کنید که باید داده های قد انسان را مدل کنید. میانگین قد آقایان در توزیع نرمال ۱ متر و ۷۷ سانتیمتر و برای خانم ها ۱ متر و ۶۶ است. در نظر بگیرید ما فقط داده های قد را می دانیم و نه جنسیتی که به آن تعلق دارند. در این حالت ، توزیع همه این قد ها، از مجموع دو توزیع نرمال تناسب یافته و انتقال یافته پیروی می کند. این فرض توسط مدل مخلوط گوسی ایجاد شده است. هر چند ، در یک GMM می تواند بیش از دو مؤلفه وجود داشته باشد. هر چند تخمین پارامترهای موجود در یک مؤلفه توزیع نرمال مجزا ، یکی از مشکلات اساسی است که هنگام مدل سازی داده ها با GMM وجود دارد.
با کمک GMM ها می توان ویژگی ها را از داده های گفتار استخراج کرد ، اشیاء متعدد را در مواردی که تعدادی از مولفه های مخلوط را در یک کلیپ ویدئویی با هدف پیش بینی موقعیت ، ردیابی کرد.
پیشنهاد می کنیم انواع مختلف الگوریتم های یادگیری ماشین را نیز بررسی کنید.
چرا ما به مدل های مخلوط گوسی نیاز داریم؟
دو حوزه رایج در یادگیری ماشین وجود دارد : یادگیری نظارت شده و یادگیری بدون نظارت . ما بر اساس ماهیت داده هایی که از آن ها استفاده می شود و رویکرد هایی که برای حل مسائل بکار برده می شوند، می توانیم به راحتی بین این دو نوع، تمایز قائل شویم. به منظور خوشه بندی نقاط بر اساس ویژگی های مشابه ، از الگوریتم های خوشه بندی استفاده می کنیم. بیایید فرض کنیم که مجموعه داده زیر را داریم:
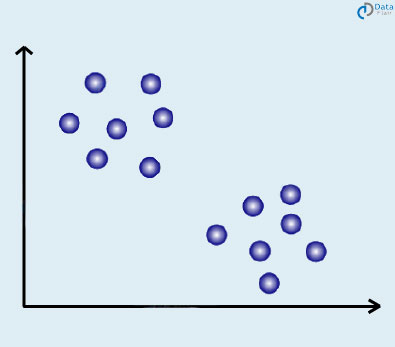
هدف ما پیدا کردن گروهی از نقاط نزدیک به هم است. دو گروه متفاوت وجود دارد که ما به رنگ آبی و قرمز در نظر می گیریم.

یکی از رایج ترین روش های خوشه بندی، الگوریتم خوشه بندی K-means است، که از یک روش تکرارشونده برای به روزرسانی پارامترهای هر یک از خوشه ها پیروی می کند. ما میانگین هر خوشه را محاسبه می کنیم که سپس با آن، میانگین هر خوشه را بدست آوریم و پس از آن، فاصله آن ها از هر نقطه داده را محاسبه کنیم. آنگاه الگوریتم، با شناسایی آن ها از طریق نزدیک ترین مرکز جرم، این نقاط داده را برچسب می زند. این روند تا رسیدن به یک معیار تغییر، تکرار می شود.
K-means ، یک الگوریتم خوشه بندی سخت است. با توجه به این، هر نقطه فقط به یک خوشه مرتبط می شود. به همین دلیل، یک عدم وجود احتمال داریم که می تواند به ما بگوید چند نقطه داده با یک خوشه خاص، مرتبط هستند. در نتیجه، از روش خوشه بندی نرم استفاده می کنیم. مدل های مخلوط گوسی گزینه مناسبی برای این کار هستند.
بسیاری از مجموعه داده ها می توانند به راحتی به کمک توزیع گوسی مدلسازی شوند. بنابراین، می توان فرض کرد که خوشه هایی از توزیع های مختلف گوسی هستند. ایده اصلی مدل این است که داده ها با مخلوطی از توزیع های گوسی مدلسازی می شوند.
تابع چگالی احتمال یک بُعدی توزیع گوسی به صورت زیر است:

دو مقدار وجود دارد که مدل مخلوط گوسی را پارامتری می کنند : وزن های مولفه، و واریانس ها / کواریانس ها . در یک مدل مخلوط گوسی با K مولفه، μk میانگین مولفه k ام است. علاوه بر این، یک مورد تک متغیره، دارای متغیر واریانس σk می باشد در حالی که یک مورد چند متغیره، دارای یک ماتریس کوواریانس Σk خواهد بود. Φk تعریف وزن های مولفه مخلوط برای هر مولفه Ck است. یک قید ∑Ki=1ϕi=۱ وجود دارد ، به گونه ای که احتمال کل به ۱ نرمال می شود.
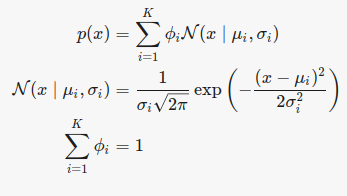
پیاده سازی مدل مخلوط گوسی
بگذارید این پیاده سازی را با بررسی نقطه ضعف خوشه بندی K-means آغاز کنیم. ما می دانیم که K-means به نتایج خوشه بندی مناسبی دست می یابد.
برای مثال، اگر مقداری نقاط داده مانند حباب های درون تصویر داشته باشیم آنگاه الگوریتم K-meansمی تواند آن خوشه ها را برچسب بزند، و کاری مشابه آنچه که ما از طریق چشم هایمان درک می کنیم، انجام دهد. به عنوان مثال ، اگر حباب های یکدستی از داده ها داشته باشیم، الگوریتم K-means می تواند به سرعت، آن خوشه ها را به گونه ای مطابق با آنچه ممکن است با چشم انجام دهیم ، برچسب گذاری کند:
کد :
%matplotlib inline
import matplotlib.pyplot as plt
import seaborn as sns; sns.set()
import numpy as np
from sklearn.cluster import KMeans
from sklearn.datasets.samples_generator import make_blobs
X, y = make_blobs(n_samples=400, centers=4,
cluster_std=0.60, random_state=0)
X = X[:, ::-1] # flipping the axes for obtaining a better plot
اسکرین شات :
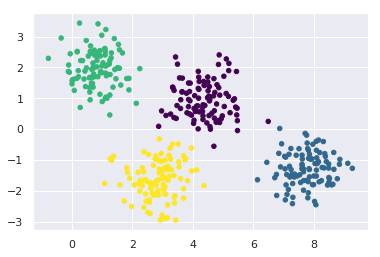
کد :
kmeans_model = KMeans(4, random_state=0) labels = kmeans_model.fit(X).predict(X) plt.scatter(X[:, 0], X[:, 1], c=labels, s=20, cmap='viridis');
اسکرین شات :

خروجی :
کد :
from sklearn.mixture import GaussianMixture as gmm gmm_model = GMM(n_components=4).fit(X) labels = gmm_model.predict(X) plt.scatter(X[:, 0], X[:, 1], c=labels, s=20, cmap='viridis');
اسکرین شات :

خروجی :

کد :
probs = gmm.predict_proba(X) print(probs[:5].round(3))
اسکرین شات خروجی :

مطالعه کاربردی GMM – قطعه بندی کلونی های همگن باکتریایی
شناسایی تصاویر دیجیتالی که در آن داده های همگن مدام تکرار می شوند، همانند تحقیقات انجام شده برای خوشه بندی کلونی های همگن باکتریایی، به منظور تخمین اندازه آن ها، انجام می گیرد. جداسازی مناطق کشت باکتریایی از ظرف، توسط قطعه بندی تصویر انجام می شود. این هیستوگرام به کمک مدل مخلوط گوسی، با استفاده از Expectation Minimization پارامتری می شود.
محققان با استفاده از این الگوریتم می توانند سطح خوبی از توزیع رنگ خاکستری را بدست آورند و توانستند توزیع جداگانه دو جسم مختلف را با یکدیگر ادغام کنند.
خلاصه
بنابراین، با به پایان رساندن این مقاله، مدل مخلوط گوسی را مورد مطالعه قرار دادیم. ما GMM را تعریف کرده و شرایط لازم برای GMM ها و نحوه پیاده سازی آن ها را مرور کردیم. علاوه بر این، ما همچنین موارد استفاده آن ها در شرکت بیوتکنولوژی را مورد مطالعه قرار دادیم. امیدوارم همه شما از این آموزش لذت برده باشید. نظرات و سؤالات خود را با ما به اشتراک بگذارید.
بیشتر بخوانید :
- فناوری تشخیص پلاک خودرو چگونه جامعه را هوشمندتر می کند
- گوگل ساختار سازمانی خود را جهت تمرکز بر هوش مصنوعی اصلاح می کند
- پلاک خوان های شهر گرینزبوروی آمریکا فعلاً قرار نیست افزایش پیدا کنند
- فرماندار اوکلند از پلاک خوان ها حمایت می کند اما مخالفان در اثربخشی آن تردید دارند
- لبنان استفاده از پلاک خوان های خودکار را تایید کرد




ممنون از مطلب خوبتون. آیا برای domain adaptation هم کاربرد دارد؟