
تقریبا از زمانی که برنامه نویسان برنامه های کامپیوتری می نوشتند، هکر های کامپیوتر، راه هایی برای افشای این برنامه ها پیدا کرده اند. هکرهای بد اندیش، از کوچک ترین خطاهای موجود در برنامه ها نهایت استفاده را می برند تا به سیستم ها دسترسی پیدا کنند ، داده را به سرقت ببرند و در کل خرابی و ویرانی به بار بیاورند.
مجموعه ی یادگیری ماشین جذاب است!

ولی سیستم هایی که بر اساس قدرت الگوریتم های یادگیری عمیق استوارند، باید در برابر دخالت های انسان ایمن باشند، درست است؟ چگونه یک هکر می تواند از یک شبکه عصبی که با ترابایت ها داده آموزش دیده است ، عبورکند؟
ظاهرا حتی پیشرفته ترین شبکه های عصبی عمیق هم می توانند به راحتی گول بخورند. با به کار بردن تعدادی از ترفند ها، شما می توانید آن ها را مجبور به پیش بینی هر نتیجه ای که می خواهید، بکنید:
خب، قبل از اینکه سیستم جدیدی را که بر پایه شبکه های عصبی عمیق راه اندازی کنید، بیایید یاد بگیریم که چگونه در آن ها اختلال ایجاد کنیم و چگونه می توانید خودتان را در برابر افراد مهاجم (هکر ها) ایمن کنید.
شبکه های عصبی به عنوان گارد های امنیتی
بیایید تصور کنیم که ما با یک وب سایت حراج اجناس مانند ebay مواجه شده ایم. در این وب سایت ما می خواهیم از اینکه مردم اجناس قدغن شده ای مانند حیوانات زنده را بفروشند، جلوگیری کنیم.
اگر شما میلیون ها کاربر داشته باشید ، به اجرا درآوردن این دسته از قوانین دشوار می باشد. می توانیم صدها نفر را اجیر کنیم تا هر لیست حراج را به صورت دستی بررسی کنند، ولی انجام این کار بسیار پر هزینه می شد. در عوض ، می توانیم از یادگیری عمیق استفاده کنیم تا به صورت خودکار عکس ها را چک کرده و چیزهای قدغن را پیدا کند و آن هایی که قوانین را زیر پا می گذارند را نشانه گذاری کند.
این یک مساله ی معمولی کلاسه بندی عکس است. برای درست کردن این برنامه، ما یک شبکه عصبی عمیق کانولوشنی آموزش خواهیم داد تا چیز های قدغن شده را از چیزهای مجاز تفکیک کند و سپس ما همه عکس ها ی سایت خود را از طریق آن پردازش خواهیم کرد.
اول، ما به مجموعه داده ای از هزاران عکس از لیست های حراج قبلی نیاز داریم. ما تصاویری از هر دو دسته ی اشیا مجاز و قدغن نیاز داریم تا بتوانیم یک شبکه عصبی برای تشخیص آن ها از یکدیگر، آموزش دهیم:

برای آموزش شبکه عصبی ما از یک الگوریتم استاندارد پس انتشار استفاده می کنیم. در این الگوریتم ، ما ابتدا یک تصویر آموزشی را در آن انتشار می دهیم ، همچنین نتیجه ی مورد انتظار را نیز به سیستم می دهیم و به هر لایه شبکه عصبی برمی گردیم و اندکی وزن هایشان را تنظیم می کند تا آن ها را برای تولید خروجی صحیح برای عکس ، بهتر کند:
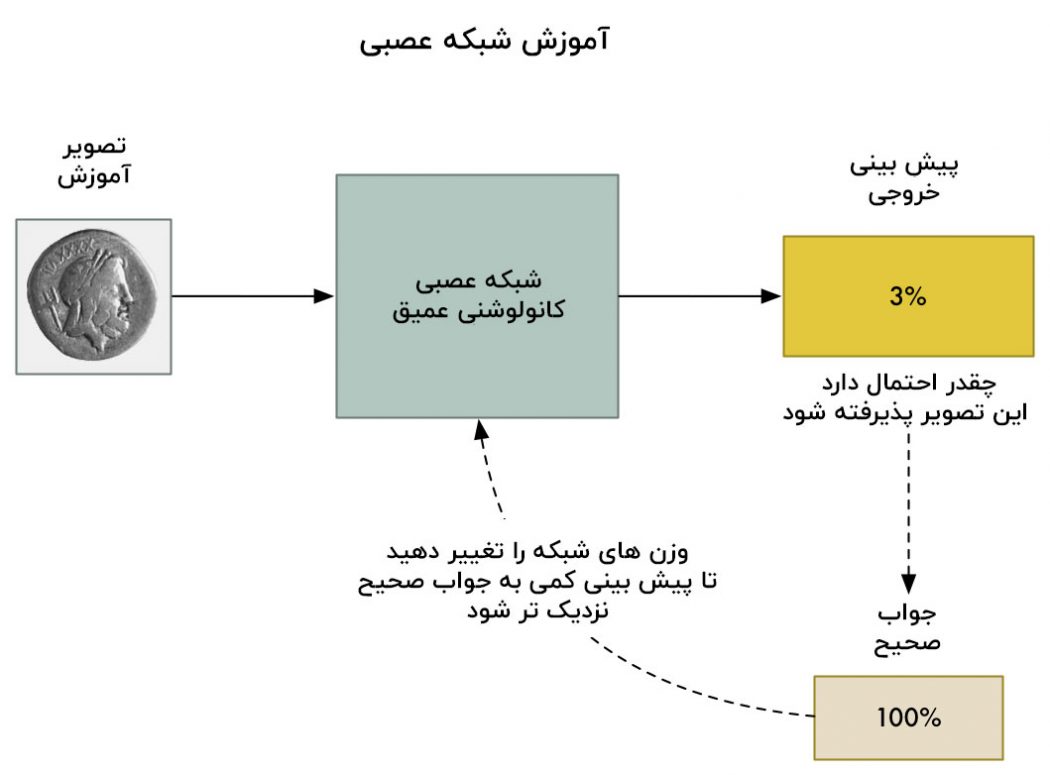
ما این کار را صد ها بار با استفاده از صد ها عکس تکرار می کنیم تا زمانی که مدل به طور قابل اعتمادی نتایج صحیح را با دقت قابل قبول تولید کند.
نتیجه نهایی یک شبکه عصبی است که می تواند عکس ها را به طور قابل اعتماد کلاسه بندی کند:

توجه: اگر شما به جزئیات بیشتری نیاز دارید تا بدانید چگونه شبکه های عصبی کانولوشنی اشیا را در تصاویر تشخیص می دهند، قسمت سوم را بخوانید.
وضعیت آنقدر ها هم که به نظر می رسد قابل اعتماد نیست…
شبکه های عصبی کانولوشنی ، مدل های قدرتمندی هستند که در هنگام کلاسه بندی عکس ها ، کل عکس را در نظر می گیرند. آن ها می توانند شکل های پیچیده و الگو ها را بدون در نظر گرفتن اینکه کجای عکس ظاهر می شوند، تشخیص دهند. در بسیاری از فرایند های تشخیص عکس، آن ها می توانند برابر و حتی بهتر از انسان باشند.
با یک مدل فوق العاده مانند این، تغییر تعداد کمی از پیکسل های عکس برای تاریک تر کردن و یا روشن تر کردن عکس، نباید اثر زیادی روی پیش بینی نهایی داشته باشد، درست است؟ مطمئناً امکان دارد احتمال نهایی را کمی تغییر دهد ولی نباید عکس را از حالت “غیر مجاز” به حالت “مجاز” تغییر دهد.

ولی در یک مقاله ی معروف در سال ۲۰۱۳ که “خواص جذاب شبکه های عصبی” نام دارد، کشف شد که این فرضیه همیشه درست نیست. اگر شما بدانید که دقیقا کدام پیکسل ها را باید تغییر دهید و همچنین دقیقا چقدر باید آن ها را تغییر دهید ، شما می توانید عمدا شبکه عصبی را مجبور کنید برای عکس داده شده، بدون تغییرات زیاد در چهره عکس، تا خروجی اشتباه را پیش بینی کند.
این بدین معناست که ما می توانیم عمدا یک تصویر را که صراحتاً غیرمجاز است را طوری تغییر دهیم که بتواند شبکه عصبی ما را گول بزند:

چرا این اتفاق می افتد؟ یک کلاسه بند یادگیری ماشین با پیدا کردن یک خط تقسیم بین چیزهایی که در تلاش است تا از هم جدا کند، کار می کند. اینجا می توانید ببینید که روی یک نمودار که برای یک کلاسه بند دو بعدی ساده می باشد که یاد گرفته است تا نقاط سبز (قابل قبول) را از نقاط قرمز (غیرقابل قبول) تفکیک کند:
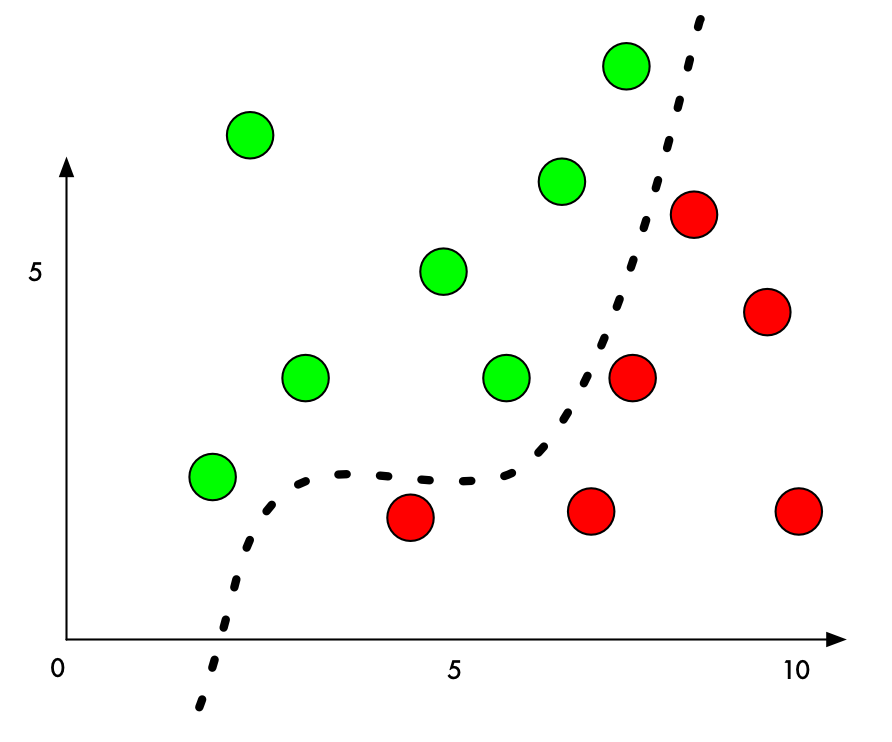
تا الان ، کلاسه بند با دقت ۱۰۰ درصدی کار می کند. یک خط پیدا شده که به طرز عالی نقاط سبز را از نقاط قرمز جدا می کند.
ولی اگر ما بخواهیم آن را فریب بدهیم تا اشتباها یکی از نقاط قرمز را به عنوان نقطه سبز کلاسه بندی کند ، کمترین مقداری که ما می توانیم یک نقطه قرمز را حرکت دهیم تا آن را به منطقه سبز وارد کنیم ، چقدر است؟
اگر ما کمی به مقدار Y نقطه قرمز که درست در کنار خط مرزی است، اضافه کنیم، می توانیم آن را در منطقه سبز بیاندازیم :
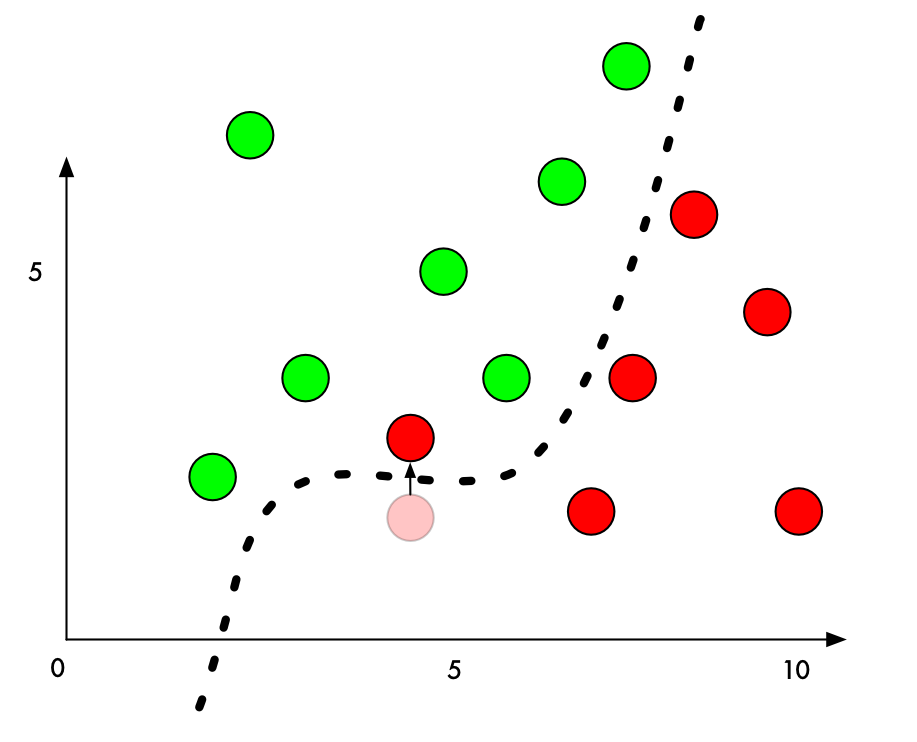
خوب برای فریب دادن یک کلاسه بند ، فقط نیاز داریم سمتی را که باید نقطه را به آن جهت حرکت دهیم تا از خط عبور کند را بشناسیم. و اگر نخواهیم که تقلب ما زیاد واضح به نظر برسد، بهترین حالت آن این است که نقطه را به کمترین مقدار ممکن حرکت دهیم ، در نتیجه شبیه یک اشتباه محرض خواهد بود.
در کلاسه بندی تصویر با شبکه های عصبی عمیق ، هر نقطه ای که ما در حال کلاسه بندی آن هستیم، یک تصویر کامل است که خود از هزاران پیکسل ساخته شده است. این هزاران مقدار متغیر ممکن را به ما می دهد تا بتوانیم آن ها را برای جابجا کردن نقطه در خط تصمیم گیری، تنظیم کنیم. و اگر ما مطمئن شویم که پیکسل ها را در تصویر به گونه ای تنظیم کرده ایم که برای انسان آنچنان واضح نباشد ، ما می توانیم کلاسه بند را بدون اینکه تصویر تغییر یافته به نظر برسد ، گول بزنیم.
به عبارت دیگر، ما می توانیم یک عکس واقعی از یک شی بگیریم و پیکسل ها را اندکی تغییر دهیم، تا تصویر شبکه عصبی را کاملاً فریب می دهد و فکر کند عکس چیز دیگری است؛ و می توانیم این که دقیقا چه چیزی را به جای تصویر اصلی تشخیص می دهد را کنترل کنیم:

چگونه شبکه عصبی را فریب دهیم
ما قبلا در مورد فرایند های کلی آموزش شبکه عصبی برای کلاسه بندی عکس ها ، صحبت کرده ایم:
- وارد کردن یک تصویر آموزشی.
- بررسی پیش بینی شبکه عصبی و مشاهده اینکه آن چقدر با پاسخ صحیح فاصله دارد.
- تنظیم وزن های هر لایه در شبکه عصبی با استفاده از پس انتشار برای نزدیک کردن پیش بینی نهایی به پاسخ صحیح.
- تکرار مراحل یک تا سه، هزاران بار با هزاران عکس آموزشی مختلف.
ولی اگر ما به جای تنظیم وزن ها در لایه های شبکه عصبی، تصویر ورودی را تنظیم کنیم تا زمانی که به پاسخ دلخواه برسیم، چطور ؟
خب بیایید شبکه عصبی که قبلا آموزش دیده است را دوباره آموزش دهیم. ولی بیاید از پس انتشار استفاده کنیم تا تصویر ورودی را به جای لایه های شبکه عصبی، تنظیم کنیم:
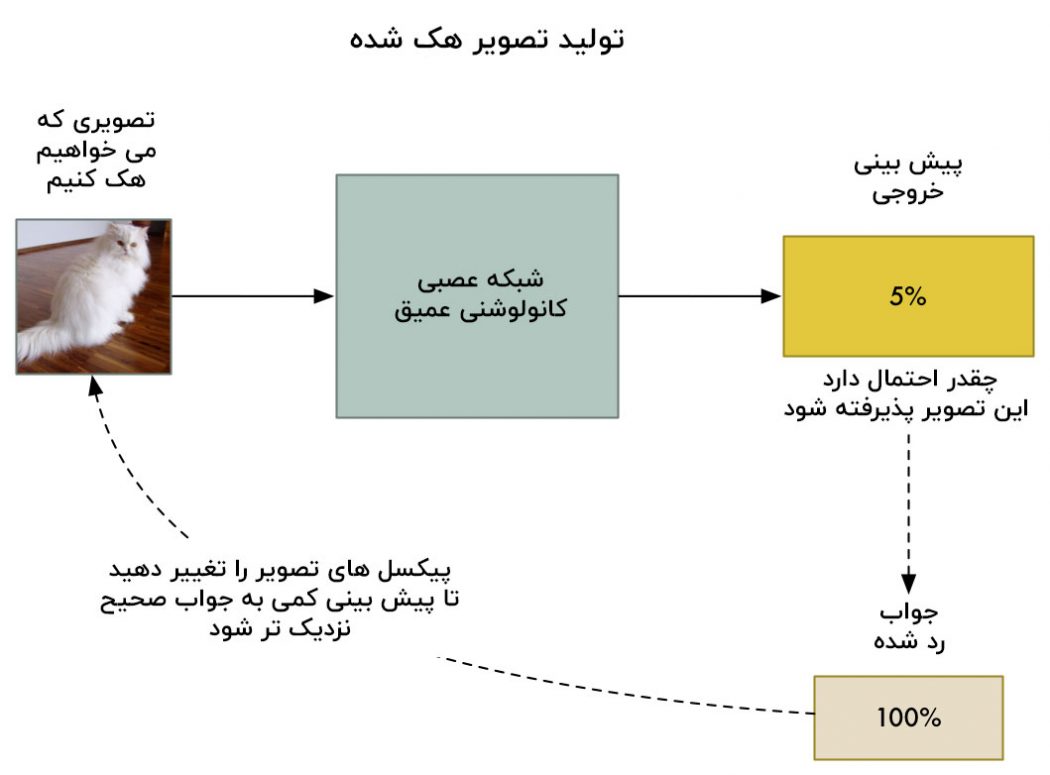
خب، اینجا الگوریتم های جدید را می بینید:
- وارد کردن تصویری که میخواهیم هک کنیم.
- پیش بینی شبکه عصبی را بررسی کنید و ببینید چقدر با جوابی که ما می خواهیم برای این عکس دریافت کنیم ، فاصله دارد.
- با استفاده از سیستم پس انتشار عکس ها را تنظیم کنید تا پیش بینی نهایی را کمی به پاسخی که می خواهیم بگیریم نزدیک کند.
- مراحل یک تا سه را هزاران بار با یک عکس یکسان تکرار کنید تا زمانی که شبکه پاسخی را که ما می خواهیم به ما بدهد.
در پایان این کار، ما یک تصویر خواهیم داشت که شبکه عصبی را فریب می دهد بدون اینکه درون خود شبکه عصبی چیزی را تغییر داده باشیم.
تنها مشکل این است که با اجازه دادن به هر پیکسل که بدون هیچ محدودیتی تنظیم شود، تغییرات تصمیم می تواند شدید تر از آن چیزی باشد که شما در آن می بینید. آن ها به عنوان نقاطی با رنگ های متفاوت یا نواحی اعوجاج یافته ظاهر خواهند شد:

برای جلوگیری از این تغییرات واضح، ما می توانیم یک محدودیت ساده به الگوریتم خود اضافه کنیم. به سیستم خواهیم گفت که هیچ پیکسلی در عکس هک شده نباید بیش از یک مقدار کوچک نسبت به عکس اصلی، دچار تغییر شود؛ بگذارید بگویم چیزی حدود ۰٫۰۱% . این محدودیت الگوریتم ما را تحت فشار قرار می دهد تا عکس را به گونه ای تنظیم کند که هنوز هم شبکه عصبی را فریب دهد آن هم بدون اینکه زیاد از عکس اصلی متفاوت به نظر برسد.
اینجا می بینید که عکس تولید شده وقتی ما محدودیت را اضافه می کنیم چگونه به نظر می رسد:

با وجود اینکه عکس از نظر ما یکسان است، این عکس هنوز هم می تواند شبکه عصبی را فریب دهد!
بیایید این را کد نویسی کنیم
برای کد نویسی این کار، اول ما به یک شبکه عصبی از قبل آموزش دیده برای فریب دادن، نیاز داریم. به جای آموزش یک شبکه از صفر، بیایید از یک شبکه که توسط گوگل ساخته شده است، استفاده کنیم.
Keras ، چارچوب معروف به یادگیری عمیق ، با تعدادی شبکه های عصبی از پیش آموزش دیده همراه است . ما از یک کپی از نسخه اصلی شبکه عصبی عمیق گوگل که Inception v3 نام دارد و برای تشخیص ۱۰۰۰ شیء مختلف از پیش آموزش دیده است، استفاده می کنیم.
اینجا کد پایه برای این که با استفاده از شبکه های عصبی تشخیص دهیم چه چیزی در یک عکس وجود دارد، را در کراس می بینید. فقط قبل از اجرای آن مطمئن شوید که پایتون ۳ و کراس روی سیستم شما نصب است :
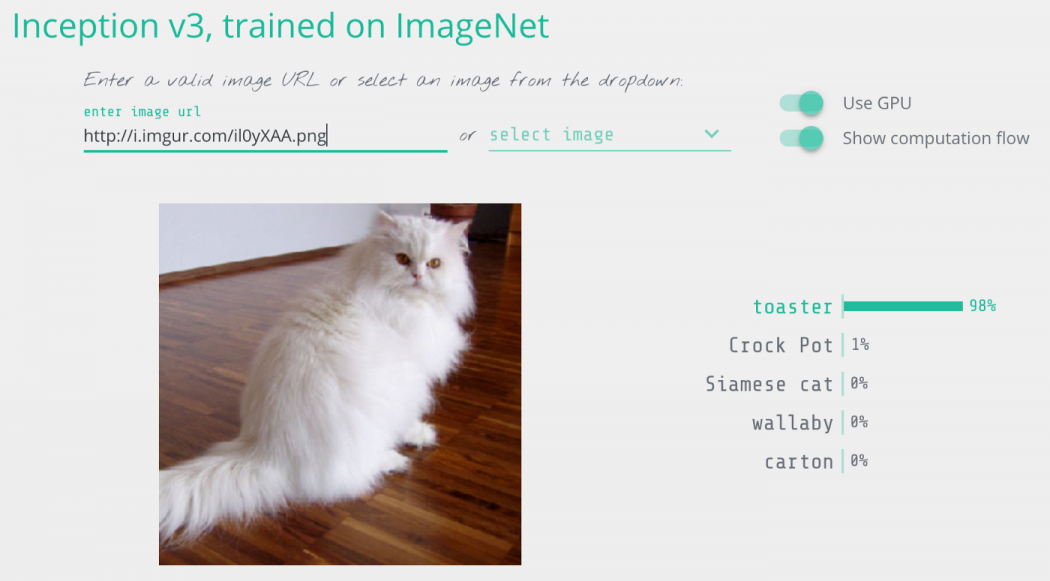
وقتی ما این کد را اجرا می کنیم، عکس ما را به خوبی به عنوان یک گربه ایرانی تشخیص می دهد:
$ python3 predict.py This is a Persian_cat with 85.7% confidence!
حال بیایید آن را گول بزنیم تا فکر کند این گربه یک تستر است. باید عکس را تغییر دهیم تا زمانی که شبکه عصبی را فریب دهد.
کراس قابلیت درونی ای برای آموزش عکس ورودی به جای آموزش لایه های شبکه عصبی ندارد، خب پس مجبور بودم تا کمی ماهر بخرج دهم و مرحله آموزش را به صورت دستی کد نویسی کنم.
اینجا کد را مشاهده می کنید:
اگر ما این کد را اجرا کنیم ، نهایتا یک تصویر به ما می دهد که شبکه عصبی ما را فریب خواهد داد:
$ python3 generated_hacked_image.py Model's predicted likelihood that the image is a toaster: 0.00072% [ .... a few thousand lines of training .... ] Model's predicted likelihood that the image is a toaster: 99.4212%
توجه : اگر شما GPU ندارید، این کار ممکن است ساعت ها طول بکشد تا اجرا شود. اگر GPU ای دارید که به خوبی توسط کراس و CUDA تنظیم شده است، اجرای آن نباید بیشتر از چند دقیقه طول بکشد.
حالا بیایید تصویر هک شده ای را که ما توسط اجرای دوباره آن روی مدل اصلی ساخته ایم ، آزمایش کنیم :
$ python3 predict.py This is a toaster with 98.09% confidence!
انجامش دادیم! ما شبکه عصبی را گول زدیم تا فکر کند گربه ، یک تستر است!
با یک تصویر هک شده چه کار هایی می توانیم انجام دهیم؟
ایجاد یک عکس مانند این “ تولید نمونه تخاصمی ” نام دارد. ما قسمتی از داده را عمدا فریب می دهیم، در نتیجه مدل یادگیری ماشین، آن را اشتباه کلاسه بندی خواهد کرد. این حقه ی خوبی است، ولی در دنیای واقعی به چه دردی می خورد؟
تحقیقات نشان داده که این تصاویر هک شده ، ویژگی های شگفت انگیزی دارند :
-
- تصاویر هک شده حتی زمانی که روی کاغذ پرینت شده اند، هنوز هم می توانند شبکه های عصبی را فریب دهند! خب پس شما می توانید از این تصاویر هک شده نه فقط در سیستم های که یک فایل تصویری را مستقیماً بارگذاری می کنند، بلکه برای فریب دادن دوربین ها و اسکنر ها نیز استفاده کنید.
- عکس هایی که یک شبکه عصبی را فریب می دهند، می توانند شبکه های عصبی دیگر را با طراحی های کاملا متفاوت فریب دهند ، در صورتی که آن ها روی داده های مشابه آموزش دیده باشند.
خب ما با این تصاویر هک شده عملا کارهای زیادی می توانیم انجام دهیم!
ولی هنوز هم یک محدودیت بزرگ در اینکه چگونه این تصاویر را به وجود آوریم ، وجود دارد؛ حمله ما نیاز به دسترسی مستقیم به خود شبکه عصبی دارد . چون ما در واقع در حال آموزش بر علیه شبکه عصبی برای فریب دادن آن هستیم؛ پس به یک کپی از آن نیاز داریم . در جهان واقعی، هیچ شرکتی این اجازه را به شما نمی دهد که کد شبکه عصبی آموزش دیده ی آن ها را دانلود کنید، خب پس این بدین معناست که ما نمی توانیم به آن ها حمله کنیم… درسته؟
جواب منفی است! محققان اخیرا نشان داده اند که شما می توانید با کاوش و جستجوی این که شبکه ی عصبی هدف چگونه رفتار می کند شبکه عصبی جایگزین خود را آموزش دهید تا شبکه عصبی اصلی را شبیه سازی کند. سپس می توانید از شبکه عصبی جایگزین خود برای تولید تصاویر هک شده که هنوز هم غالباً شبکه اصلی را فریب می دهند ، استفاده کنید! این حمله جعبه سیاه نام دارد.
کاربرد های های حمله جعبه سیاه نامحدود هستند. اینجا برخی از نمونه های محتمل را می بینید:
ماشین های خودران را گول می زنیم تا علامت ایست را به عنوان چراغ سبز ببیند؛ این می تواند باعث تصادف خودرو ها شود!
سیستم های فیلترینگ را گول بزنیم تا به مضامین تهاجمی/ غیرقانونی اجازه فعالیت دهد.
خودپرداز های اسکنر چک را فریب می دهیم تا فکر کند که دست نویس های روی چک مقدار بیشتری از مقدار واقعی را نشان می دهد. (و اگر شما بازداشت شوید، امکان انکار وجود دارد!)
ولی این روش های حمله، محدود به عکس ها نیست. شما می توانید همین مدل از رویکرد را برای فریب دادن کلاس بند هایی که روی انواع دیگری از داده ها کار می کند، استفاده کنید. برای مثال، شما می توانید نرم افزار های ویروس یاب را فریب دهید تا ویروس شما را به عنوان رمز صحیح شناسایی کند!
چگونه می توانیم خود را در برابر این حملات ایمن کنیم؟
خب حالا که ما می دانیم فریب دادن شبکه های عصبی ( و همچنین همه انواع دیگر مدل های یادگیری ماشین ) ممکن است، چگونه می توانیم در برابر آن از خود دفاع کنیم؟
جواب کوتاه این است که هنوز هیچ کس مطمئن نیست. پیشگیری از این دسته از حملات هنوز یک حوزه ی در حال تحقیق و بررسی است. بهترین راه برای دستیابی به آخرین پیشرفت ها، خواندن وبلاگ Cleverhans است که توسط Ian Goodfellow و Nicolas Papernot ، دو تن از تاثیر گذار ترین محققان در این زمینه اداره می شود.
ولی چیزهایی که ما تاکنون می دانیم:
-
- اگر شما فقط تعداد زیادی از تصاویر هک شده ایجاد کنید و آن ها را در مجموعه داده آموزشی خود قرار دهید ، به نظر می رسد که شبکه عصبی شما در برابر حملات، مقاوم تر شود. این کار آموزش تخاصمی نام دارد و احتمالا در حال حاضر منطقی ترین راه دفاع برای تطبیق با این حملات است.
- رویکرد دیگر که اندکی تاثیرگذار است، تقطیر تدافعی ( Defensive Distillation ) نام دارد و شما مدل دومی را آموزش می دهید تا از مدل اصلی تقلید کند. ولی این یک رویکرد جدید و تا حدودی پیچیده است، پس فعلا من روی این روش سرمایه گذاری نمی کنم ، مگر اینکه شما نیازهای ویژه و تخصص یافته ای داشته باشید.
- نظریه های دیگری وجود دارند که محققان تاکنون آن ها را امتحان کرده اند ولی از نظر پیشگیری از این حملات ، موثر نبودند.
از آنجایی که ما هنوز هیچ پاسخ نهایی ای نداریم، ارزش آن را دارد که وقتی که در حال استفاده از شبکه های عصبی هستید در مورد سناریو هایی فکر کنید که این مدل از حملاتی که ممکن است به شما آسیب بزنند، را به حداقل برساند.
برای مثال، اگر شما یک مدل یادگیری ماشین را به عنوان تنها خط دفاعی برای اجازه دسترسی به یک منبع محصور داشته باشید و فرض کنید که هیچ گاه فریب نمی خورد، احتمالا نظریه ای بد است . ولی اگر شما یادگیری ماشین را به عنوان روندی که هنوز هم تایید بشر در آن نیاز است، استفاده کنید، آن احتمالا بهتر جواب خواهید گرفت.
یادگیری بیشتر
آیا می خواهید در مورد نمونه های تخاسمی و ایمن بودن در برابر آن ها بیشتر یاد بگیرید؟
-
- این حوزه ی تحقیقاتی تنها چند سال عمر دارد، پس به آسانی با خواندن چند مقاله ی کلیدی می توانید در این حوزه به روز باشید: فریفتن مقادیر های شبکه عصبی، توضیح و مهار کردن نمونه های تخاصمی، حملات جعبه سیاه ویژه بر علیه یادگیری ماشین و نمونه های تخاصمی در دنیای فیزیکی.
- وبلاگ Cleverhans از Ian Goodfellowو Nicolas Papernot را دنبال کنید تا با تحقیقات اخیر آن ها پیش بروید.
- رقابت های پیاپی Kaggle را که محققان را به چالش کشیده تا با راه های جدیدی برای دفاع در برابر این حملات آشنا شوند را دنبال کنید.
اگر شما این متن را دوست داشتید، لطفا برای ما نظر بگذارید تا از دیدگاه و حوزه های مورد علاقه ی شما با خبر شویم. منتظر شنیدن انتقادات و پیشنهادات شما هستیم.
بیشتر بخوانید :
- پلاک خوان های شهر گرینزبوروی آمریکا فعلاً قرار نیست افزایش پیدا کنند
- فرماندار اوکلند از پلاک خوان ها حمایت می کند اما مخالفان در اثربخشی آن تردید دارند
- لبنان استفاده از پلاک خوان های خودکار را تایید کرد
- چالش های مدیریت کلاس با ابزار جدید تشخیص چهره هوش مصنوعی
- آیا می توان از دوربین های ترافیکی برای گرفتن رانندگان الکلی استفاده کرد؟



