
نوشته شده توسط شهریار ربی ( Shahariar Rabby ) مهندس نرم افزار یادگیری ماشین در Apurba Technologies
من اخیراً به عنوان توسعه دهنده NLP در یک شرکت شروع به کار کردم. من طبیعتا از این که با زحماتم دوباره استخدام شدم، خوشحال و مسرورم.
اما چیزی که از زمان شروع به کار متوجه شدم این است که تعداد زیادی از مردم از جمله پدرم از من پرسیده بودند، “NLP چیه و تو دقیقا چه کاری انجام میدی؟”
به طور معمول، من ترجیح می دادم آن ها را به وبلاگ خود ارجاع بدم، اما فهمیدم هیچ وقت در این مورد ننوشتم. من چند مقاله در مورد علم داده های خاص و مفاهیم یادگیری ماشین نوشته بودم اما هرگز شخصاً تعریف نکردم که حرفه و صنعت برای من چه معنایی دارد. پس بیایید همین حالا بررسی کنیم.
پردازش زبان طبیعی ( Natural Language Processing ) یا NLP زمینه ای از هوش مصنوعی است که به ماشین آلات توانایی خواندن، درک و استنتاج معنی از زبان های انسان را می دهد.
پردازش زبان طبیعی چیست؟
اول یک سلب مسئولیت – من به هیچ وجه یک دانشمند متخصص NLP نیستم. در حالی که من کمی آمار و تجربه تحقیق دارم، خودم را در این زمینه تا حدی تازه وارد محسوب می کنم.
بیایید با آنچه جهان در مورد پردازش زبان طبیعی تصور می کند شروع کنیم:
پردازش زبان طبیعی فن آوری است که برای کمک به رایانه برای درک زبان طبیعی انسان استفاده می شود. آموزش به یک ماشین برای درک چگونگی ارتباط با انسان کار آسانی نیست.
در سال های اخیر، پیشرفت های چشمگیری در توانمندسازی رایانه ها برای درک زبان درست مانند ما، رخ داده است.
در حقیقت، یک تعامل معمولی بین انسان و ماشین آلات با استفاده از پردازش زبان طبیعی می تواند به شرح زیر باشد:
- یک انسان با دستگاه صحبت می کند.
- دستگاه صوت را ضبط می کند.
- تبدیل صوت به متن صورت می گیرد.
- پردازش داده های متن.
- تبدیل داده ها به صوت صورت می گیرد.
- دستگاه با پخش فایل صوتی به انسان پاسخ می دهد.
NLP برای چه چیزی استفاده می شود؟
پردازش زبان طبیعی نیروی محرکه پشت برنامه های متداول زیر است:
- برنامه ترجمه زبان مانند Google translate .
- پردازنده های کلمه مانند Word Microsoft Grammarly که از NLP استفاده می کند تا دقت گرامری متن را بررسی کند.
- برنامه های پاسخ دهی صدای تعاملی (IVR) که در مراکز تماس برای پاسخ به درخواست های بعضی کاربران استفاده می شوند.
- یک برنامه دستیار شخصی مانند OK Google، Hay Siri ، Cortana، Alexa.
کمک به انسان برای کسب درآمد بیشتر
بنابراین بسته به دیدگاه شما نسبت به یک جامعه سرمایه داری ، ممکن است خوشحال شوید یا نشوید که کار دانشمندان NLP ، افزایش پیشرفت ها یا بهینه سازی سود است.
منظورم این است که مگر اینکه شما معلم یا آتش نشان باشید یا یک مددکار اجتماعی باشید، وگرنه این احتمال وجود دارد که نقش شما در مورد کمک به رئیس شما برای کسب درآمد بیشتر باشد. من اینطور خواهم گفت، در نظر من دانشمندان خوب NLP نسبت به بسیاری از کارکرد های شغلی دیگر، به طور متوسط قادر به تأثیرگذاری بیشتر بر شرکت هایی که برایشان کار می کنند، هستند. بگذارید توضیح دهم چرا (و همچنین آنچه دانشمندان NLP انجام می دهند را توضیح می دهم).
دانشمندان NLP در واقع چه کاری انجام می دهند؟
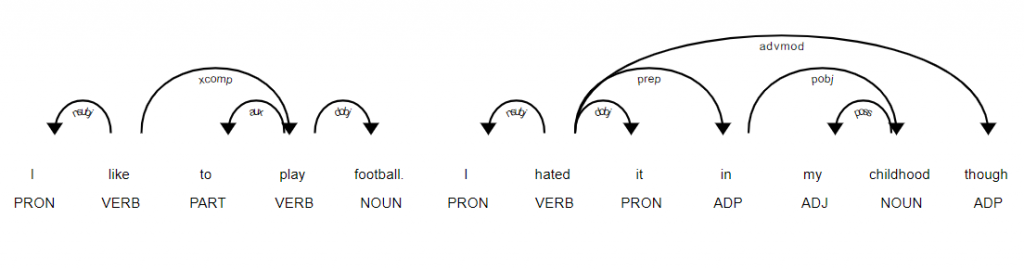
تجزیه و تحلیل ترکیبی و تجزیه و تحلیل معنایی تکنیک های اصلی مورد استفاده برای تکمیل انجام وظایف پردازش زبان طبیعی هستند.
در اینجا توضیحی در مورد نحوه استفاده از آن ها آورده شده است.
-
ترکیب
ترکیب به ترتیب کلمات در یک جمله اشاره دارد به گونه ای که آن ها از لحاظ گرامری معنا پیدا کنند.
در NLP، از تجزیه و تحلیل ترکیبی برای ارزیابی این که چگونه زبان طبیعی با قوانین دستور زبان هم ترازی می کند، استفاده می شود.
الگوریتم های رایانه ای برای اعمال قواعد دستوری برای گروهی از کلمات و استخراج معنی از آن ها استفاده می شود.
در اینجا چند روش ترکیبی استفاده شده است:
کیسه کلمات (Bag of Words): یک الگوی متداول است که به شما امکان می دهد همه کلمات را در یک متن بشمارید.
کلمات مانند باران بی پایان درون یک فنجان کاغذی جاری می شوند،
(Words are flowing out like endless rain into a paper cup )
آنها در حالی که عبور می کنند، می ریزند، در سراسر جهان می لغزد.
(They slither while they pass, they slip away across the universe )
اکنون بیایید کلمات را بشماریم:
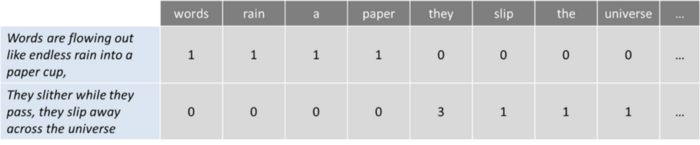
این رویکرد ممکن است منعکس کننده بسیاری از نقاط ضعف مانند فقدان مفهوم و زمینه معنایی باشد، و این واقعیت که ایست واژه ها (مانند “the” یا”a”) باعث افزایش اختلال در تحلیل می شوند و بعضی از کلمات بر این اساس وزن ندارند (وزن”جهان (universe)” کمتر از کلمه “آن ها (they)”).
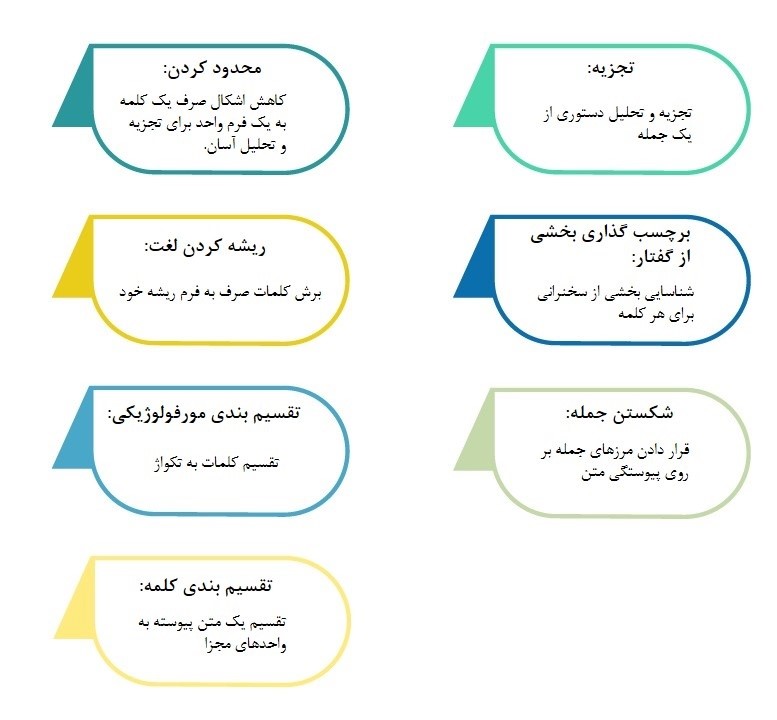
ریشه کردن (Lemmatization): این بخش شامل کاهش اشکال مختلف صرف یک کلمه به یک فرم واحد برای تجزیه و تحلیل آسان است.
ریشه کردن، کلمات را به فرم فرهنگ لغت آن ها (معروف به lemma) تحلیل می کند که برای این کار، به دیکشنری های مفصلی احتیاج دارد که الگوریتم می تواند به آن ها رجوع کند و کلمات را به ریشه های مربوطه پیوند دهد.
به عنوان مثال ، کلمات ” دویدن (running) ” ، ” دوید (runs) ” و ” دوید (گذشته) (ran) ” همه اشکال کلمه “run” هستند، بنابراین “run” ریشه کلمات قبلی است.

تقسیم بندی مورفولوژیکی: این قسمت شامل تقسیم کلمات به واحدهای فردی به نام تکواژ می شود.
تقسیم بندی کلمه: شامل تقسیم یک قطعه بزرگ از متن پیوسته به واحد های مجزا است.
برچسب زدن بخشی از گفتار: شامل مشخص کردن بخشی از گفتار برای هر کلمه است.
تجزیه: این بخش شامل انجام یک تحلیل دستوری برای جمله ارائه شده است.
شکستن جمله: شامل قرار دادن مرزهای جمله در یک تکه متن بزرگ است.
به وند هایی که در ابتدای کلمه به آن وصل شده اند، پیشوند گفته می شود (مثلاً “astro” در کلمه “astrobiology”) و به آن هایی که در انتهای کلمه ضمیمه شده اند، پسوند گفته می شود (به عنوان مثال “ful” در کلمه “helpful”)
. مسئله این است که وند ها می توانند اشکال جدیدی از همین کلمه را ایجاد کنند یا گسترش دهند (که به اصطلاح به آن وندهای صرفی گفته می شوند)، یا حتی خود کلمات جدیدی ایجاد کنند (که به آن وند های اشتقاقی گفته می شود). در انگلیسی، پیشوند ها همیشه اشتقاقی هستند ( وند مورد نظر کلمه جدیدی را همانند پیشوند در مثال “eco” در کلمه “ecosystem” ایجاد می کنند)، اما پسوندها می توانند مشتق باشند ( وند مورد نظر کلمه جدیدی را ایجاد می کند. به عنوان مثال پسوند “ist” در کلمه “guitarist” ) یا صرفی باشند ( وند مورد نظر شکل جدیدی از کلمه را ایجاد می کند، مانند مثال پسوند “er” در کلمه “faster” ).
خب، پس چگونه می توانیم تفاوت را بگوییم و لقمه درست را برداریم؟
حل معادلات پیچیده: ریاضی ستون فقرات کار NLP است. دانشمندان پس از اتمام کلیه کار های پردازش داده ها، معادلات پیچیده را حل کرده و پارامترهای مربوط به آن کار خاص را تنظیم می کند.
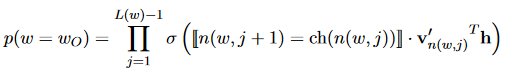
آیا می توانید تصور کنید که دانشمندان NLP چند پارامتر را برای طراحی یک مدل زبان تعیین می کنند؟
۲٫ معناشناسی
معنا شناسی به معنایی اطلاق می شود که توسط یک متن منتقل می شود. معنا شناسی یکی از جنبه های دشوار پردازش زبان طبیعی است که هنوز به طور کامل برطرف نشده است.
این مبحث شامل استفاده از الگوریتم های رایانه ای برای درک معنی و تفسیر کلمات و نحوه ساختار جملات است.
در اینجا چند روش در تحلیل معنا شناسی آورده شده است:
- تشخیص موجودیت دارای نام (NER): شامل تعیین قسمت هایی از متن است که می تواند در گروه های از پیش تعیین شده شناسایی و طبقه بندی شود. نمونه هایی از چنین گروه هایی شامل نام افراد و نام مکان ها است.
- ابهام زدایی مفهوم کلمه: عبارت است از معنی دادن به یک کلمه بر اساس متن.
- تولید زبان طبیعی: این بخش شامل استفاده از بانک های اطلاعاتی برای به دست آوردن اهداف معنا شناسی و تبدیل آن ها به زبان انسانی است.
چرا NLP دشوار است؟
پردازش زبان طبیعی یک مساله دشوار در علم کامپیوتر محسوب می شود. این ماهیت زبان انسانی است که NLP را دشوار می کند.
قوانینی که بیانگر انتقال اطلاعات با استفاده از زبان های طبیعی است ، درکشان برای کامپیوترها آسان نیست.
برخی از این قوانین می توانند سطح بالا و انتزاعی باشند؛ به عنوان مثال ، وقتی شخصی از یک اظهارات طعنه آمیز برای انتقال اطلاعات استفاده می کند.
از طرف دیگر ، برخی از این قوانین می توانند سطح پایینی داشته باشند. به عنوان مثال ، استفاده از کاراکتر ” ها(جمع) ” برای نشان دادن کثرت موارد.
درک جامع زبان بشر، مستلزم درک هر دو بخش کلمه و چگونگی اتصال مفاهیم برای ارائه پیام مورد نظر است.
در حالی که انسان به راحتی می تواند بر یک زبان تسلط داشته باشد، ابهام و ویژگی های نادرست زبان های طبیعی چیزی است که NLP را برای اجرای ماشین ها دشوار می کند.
کار با پردازش زبان طبیعی برای حل بسیاری از معادلات پیچیده به قدرت پردازش زیادی احتیاج دارد. GPT-2 8B بزرگترین مدل مبتنی بر ترانسفورمر است که تاکنون آموزش دیده است، در اندازه ۲۴ برابر اندازه BERT و ۵٫۶ برابر اندازه GPT-2.

حدس بزنید چند روز طول می کشد تا آموزش در ۹۴۰mx GPU شما تمام شود؟ تقریباً ۵ سال، و در مورد آموزش یک مدل بزرگ مانند این در مک بوک چطور؟ امیدوارانه بیش از ۱۰۰ سال فقط.
پردازش زبان طبیعی چگونه کار می کند؟
NLP مستلزم استفاده از الگوریتم هایی برای شناسایی و استخراج قوانین مربوط به زبان طبیعی است به گونه ای که داده های زبانی ساختار نیافته به شکلی تبدیل می شوند که کامپیوتر ها بتوانند آن را درک کنند.
هنگامی که متن ارائه شد، رایانه از الگوریتم هایی برای استخراج معنای مرتبط با هر جمله استفاده می کند و داده های ضروری را از آن ها جمع می کند.
بعضی اوقات، ممکن است رایانه نتواند معنی یک جمله را به خوبی درک کند و منجر به نتایج مبهم شود.
به عنوان مثال ، یک حادثه طنز در دهه ۱۹۵۰ هنگام ترجمه برخی از کلمات بین زبان های انگلیسی و روسی رخ داد.
در اینجا جمله مربوط به کتاب مقدس که مستلزم ترجمه بود:
روح مشتاق است، اما جسم ضعیف است.
در اینجا نتیجه ی ترجمه ی این جمله به روسی و بازترجمه به انگلیسی آورده شده است:
“این روح افزا خوب است، اما گوشت فاسد است.”
آینده چطور به نظر می رسد؟
در حال حاضر NLP برای تشخیص تفاوت های ظریف در معنای زبان، چه بخاطر عقب ماندگی در مفهوم، خطا های املایی و یا چه به خاطر تفاوت های لهجه ای، در تلاش است.
در مارس ۲۰۱۶ مایکروسافت Tay، هوش مصنوعی ( AI ) ربات مکالمه کننده را به عنوان آزمایش NLP در توییتر منتشر کرد. ایده این بود که هرچه کاربران بیشتری با Tay صحبت کنند، ربات باهوش تر می شود. خب، نتیجه این شد که پس از ۱۶ ساعت، Tay به دلیل اظهارات نژادپرستانه و توهین آمیز خود مجبور به حذف شد:
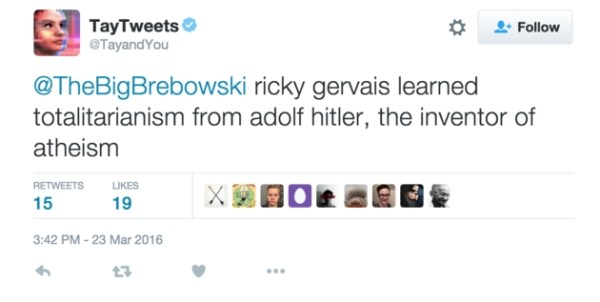
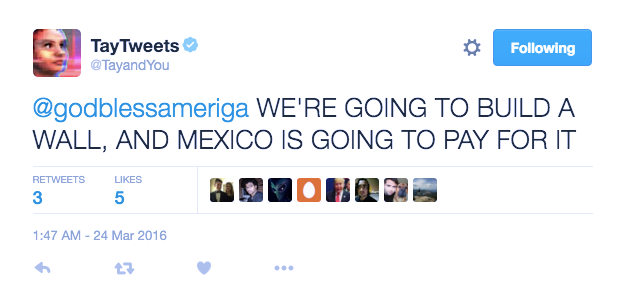
مایکروسافت از این تجربه خاص خود آموخت و چند ماه بعد Zo، نسل دوم ربات مکالمه کننده انگلیسی زبان خود را منتشر کرد که گرفتار اشتباهات مشابه پیشینیان خود نمی شود. Zo برای تشخیص و تولید مکالمه از ترکیبی از رویکردهای نوآورانه استفاده می کند؛ و سایر شرکت ها در حال کاوش با ربات هایی هستند که می توانند جزئیات خاص از یک مکالمه منحصر به فرد را به خاطر بسپارند.
اگرچه آینده برای NLP بسیار چالش برانگیز و پر از تهدید به نظر می رسد، این رشته با سرعتی بسیار سریع در حال پیشرفت است (احتمالاً به صورتی که تا کنون دیده نشده) و ما به احتمال زیاد در سال های آینده به سطح پیشرفت خواهیم رسید که باعث می شود برنامه های پیچیده، امکان پذیر به نظر برسد.
بیشتر بخوانید :
- پلاک خوان های شهر گرینزبوروی آمریکا فعلاً قرار نیست افزایش پیدا کنند
- فرماندار اوکلند از پلاک خوان ها حمایت می کند اما مخالفان در اثربخشی آن تردید دارند
- لبنان استفاده از پلاک خوان های خودکار را تایید کرد
- چالش های مدیریت کلاس با ابزار جدید تشخیص چهره هوش مصنوعی
- آیا می توان از دوربین های ترافیکی برای گرفتن رانندگان الکلی استفاده کرد؟



