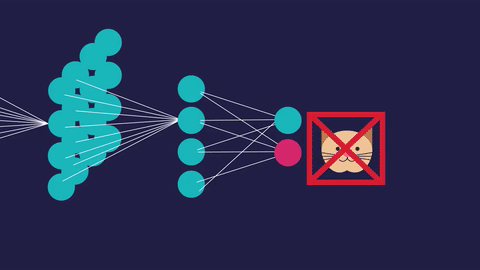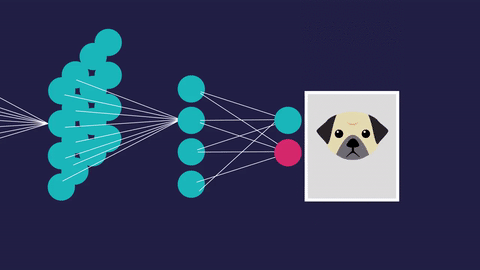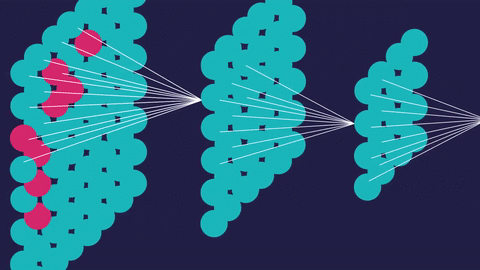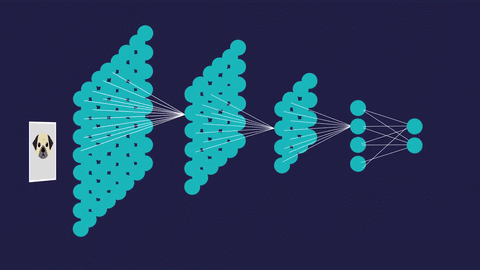
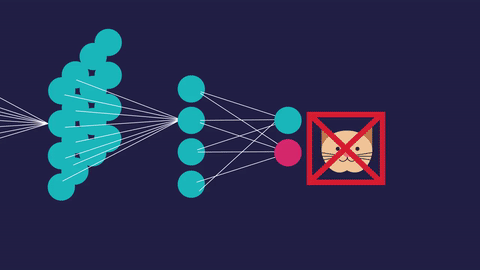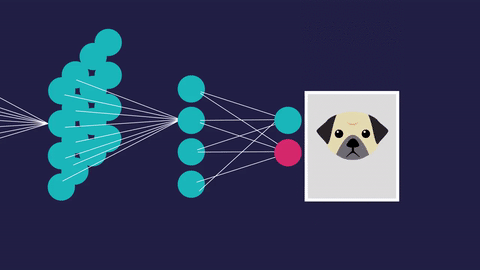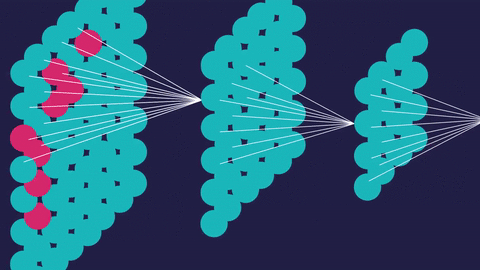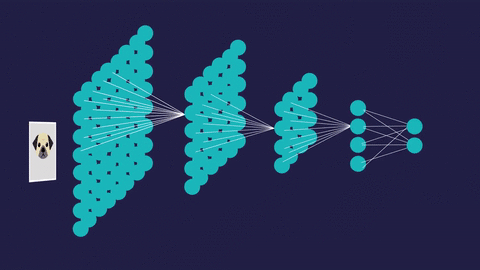
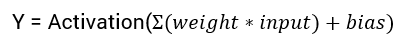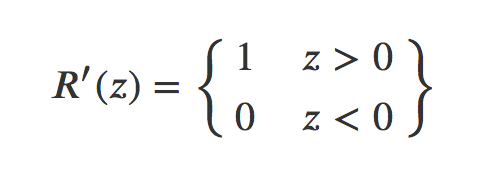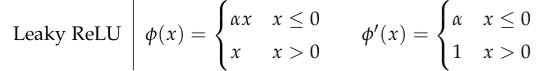“The expert in anything was once a beginner” -Helen Hayes
Yes, let me begin the initial step of yours in deep learning by teaching you the two basic and important concepts in deep learning i.e.,Activation functions and weight initialization in deep learning.
Activation functions
Introduction
For everything there is biological inspiration. Activation functions and neural networks are one of the beautiful ideas inspired from humans. When we feed lots of information to our brain, it tries hard to understand and classify the information between useful and not so useful information. In the same way, we need similar mechanism to classify the incoming information as useful and not useful in case of neural networks. Only some part of information is much useful and rest may be some noise. Network tries to learn the useful information. For that, we need activation functions. Activation function helps the network in doing segregation. In simpler words, activation function tries to build the wall between useful and less useful information.
Let me introduce you to some terminologies, in order to simplify understanding .
Neural networks
Let me give a simple example and later i will connect the dots with the theory. Suppose, we are teaching an 8 year old kid to perform addition of two numbers. First of all, he will receive the information about how to perform addition from the instructor. He now tries to learn from the information given and finally , he performs addition. Here, the kid can be thought as neuron, it tries to learn from the input given and finally from the neuron we will get output.
In biological perspective, this ideal is similar to human brain . Brain receives the stimulus from outside world, does processing on the input and then generates the output. As the task gets more complex, multiple neurons form a complex network passing information among themselves.
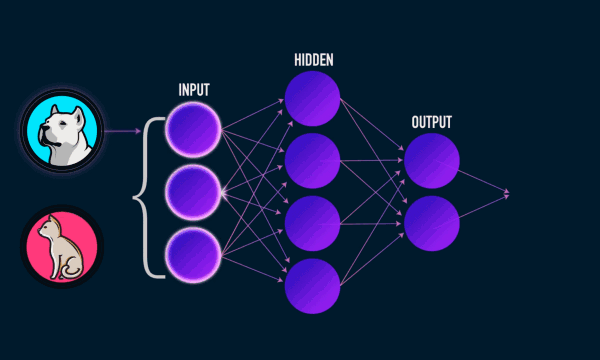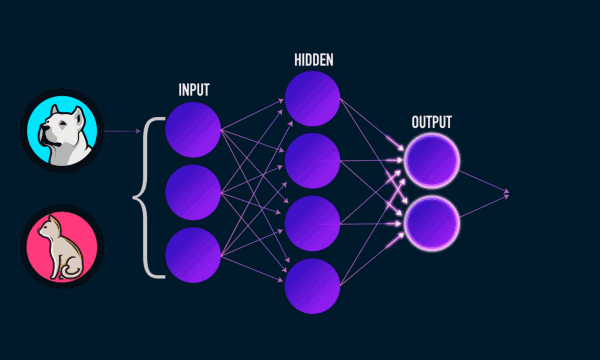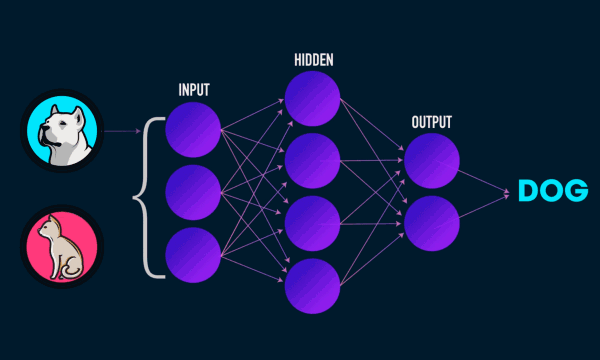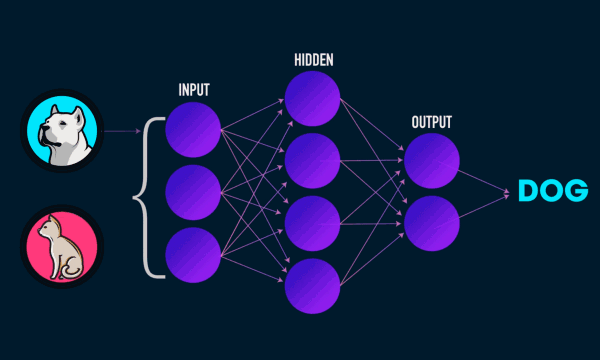
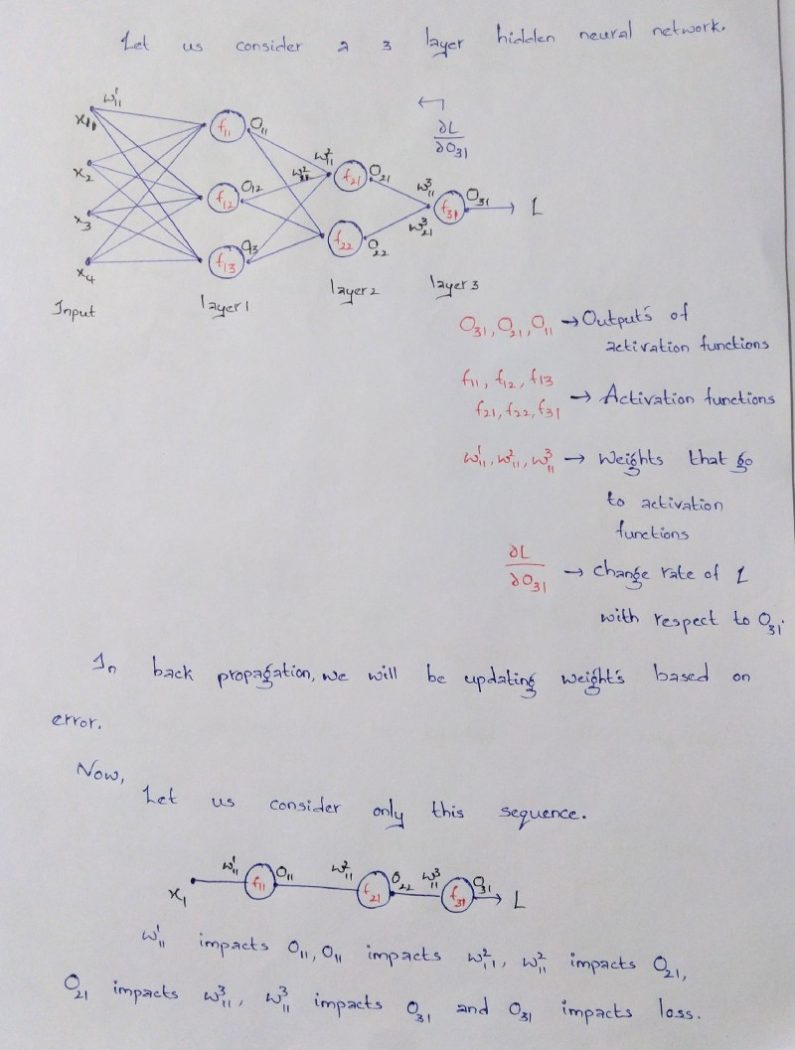
The blue circles are the neurons. Each neuron has weight,bias and activation function. Input is fed to the input layer. The neuron then performs a linear transformation on the input by the weights and biases. The non linear transformation is done by the activation function.The information moves from input layer to hidden layer. Hidden layer would do the processing and gives output. This mechanism is forward propagation.
What if the output generated is far away from the expected value?
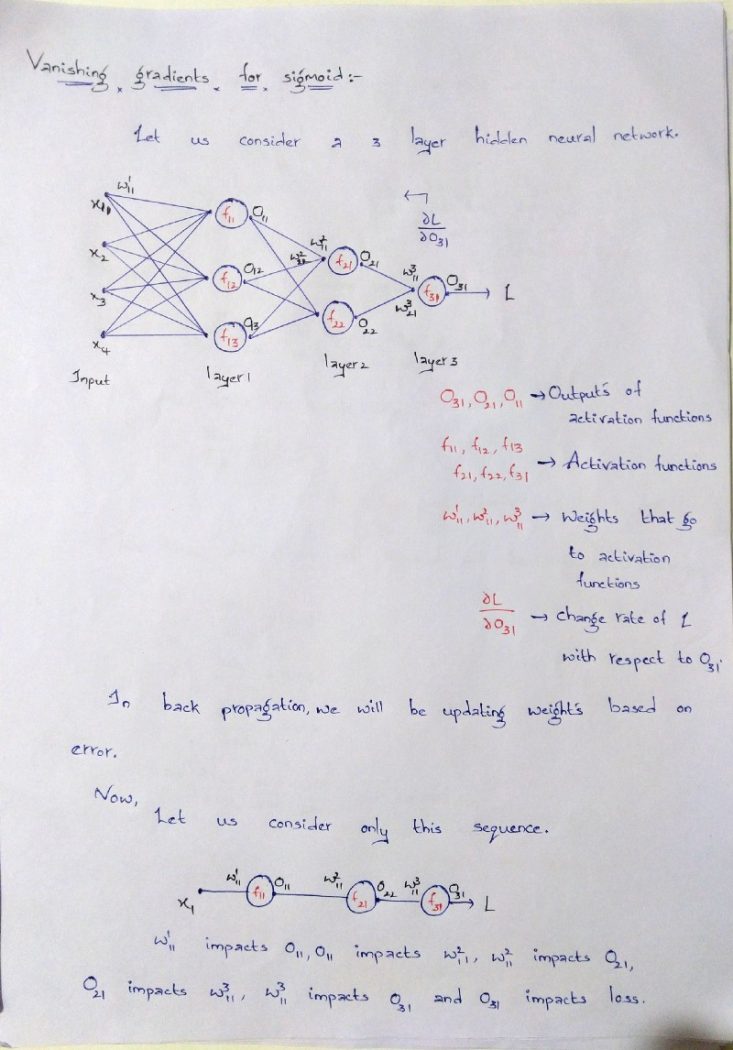
In neural network, we would update the weights and biases of the neurons on the biases of error. This process is known as back propagation. Once the entire data has gone through this process, final weights and biases are used for predictions.
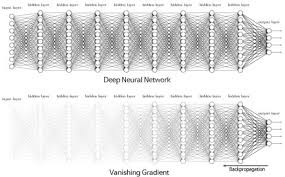
Vanishing gradients
Generally, adding more number of hidden layers in the network will allows it to learn more complex functions, thus it performs well.
But, here comes the problem, when we do back propagation i.e., calculating and updating the weights in backward direction,the gradients tends to get smaller and smaller as we keep on moving backwards in the network. This means the weights of the neurons in the earlier layers learn very slowly or sometimes they won’t change at all .But earlier layers in the network are much important because they are responsible for detecting simple patterns. If the earlier layers give inappropriate results,then how can we expect our model to perform well in later layers. This problem is called vanishing gradient problem.
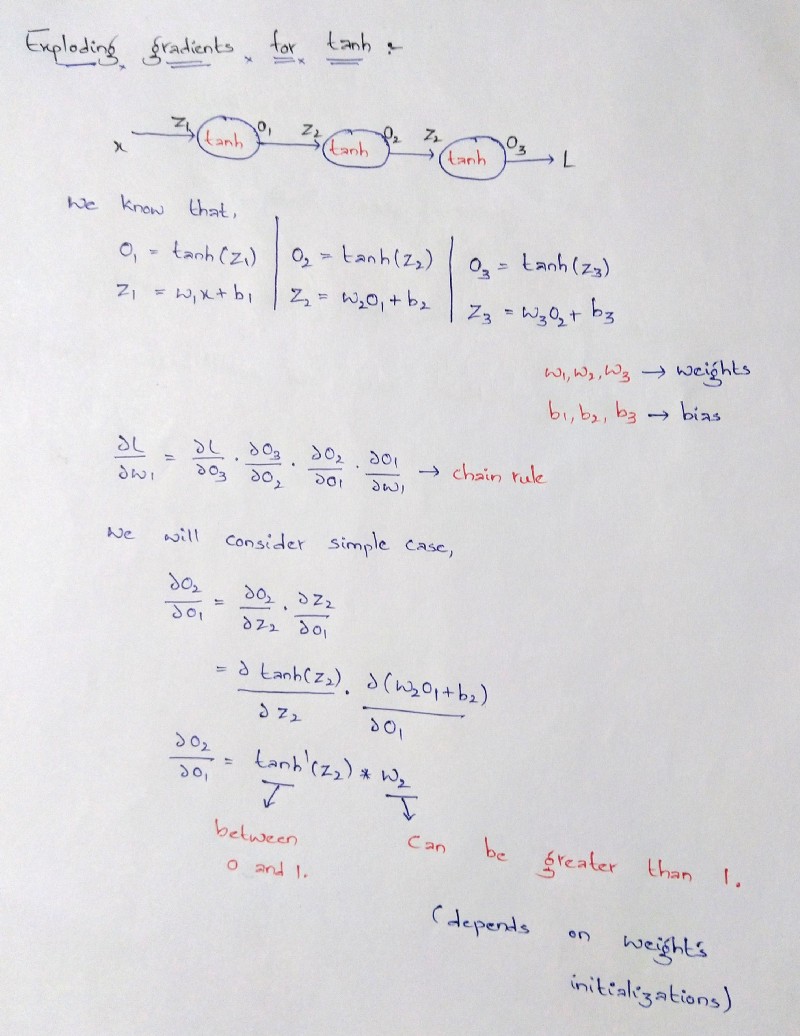
Exploding gradients
We know that, when we have more number of hidden layers, our model tends to perform well. When we do back propagation, if the gradients become larger and larger, then the weights of the neurons in the earlier stages change much. We know that the earlier layers are much important. Because of this larger weights, the neurons in the earlier layers will give inappropriate results. This problem is called exploding gradients problem.
Now, let us dive deep into core concept of activation functions.
What is an activation function ?
“ An activation function is a non-linear function applied by the neuron to introduce non-linear properties in the network.”
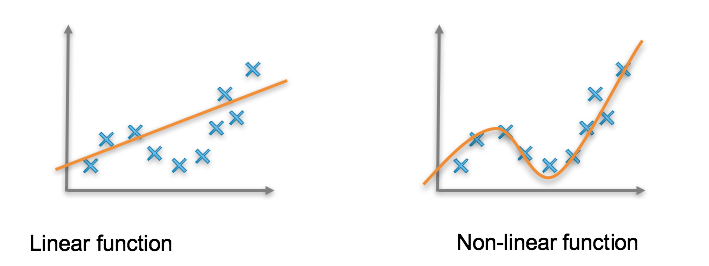
Let me explain in detail. There are two types of functions i.e., linear and non-linear functions.
Linear function
If the change in the first variable corresponds to a constant change in the second variable, then we call it as linear function.
Non-linear function
If the change in the first variable doesn’t necessarily correspond with a constant change in the second variable, then we call it as non-linear function.
Why we use activation functions ?
In simple case of any neural network, we multiply weights with the input, add bias and apply an activation function and pass the output to the next layer and we do back propagation to update the weights.
Neural networks are functions approximators. The main goal of any neural network is to learn complex non-linear functions. If we don’t apply any non-linearity in our neural network, we are just trying to separate the classes using a linear hyper plane. As we know, nothing is linear in this real world.
If we perform simple linear operation i.e., multiply the input by weight,add a bias term and sum them across all the inputs arriving to the neuron. In some cases, the output of the above values is very large. When, this output is fed to the further more layers, the values become even more larger , making things computationally uncontrollable. This is where the activation function plays a major role i.e., activation function squashes the input real number to a fixed interval i.e., (between -1 and 1) or (between 0 and 1) .
Let us discuss about the different activation functions and their problems
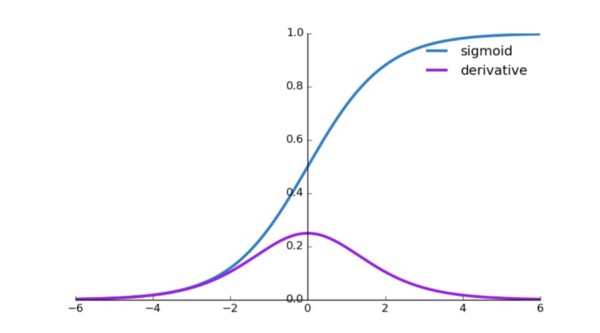
Sigmoid
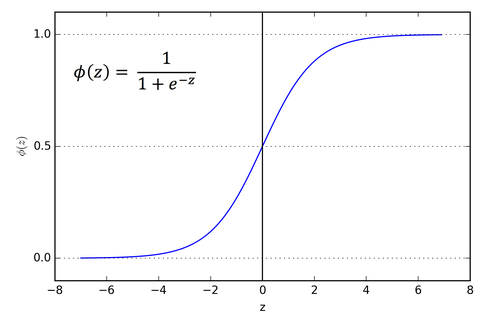
Sigmoid is a smooth function and is continuously differentiable. This is a non-linear function and it looks like S- shape.Main reason to use sigmoid function is, its value exists between 0 and 1. Therefore, it is especially used for models where we have to predict the probability as an output. Since probability of anything exists between the range 0 and 1, sigmoid is right choice.
As we know, sigmoid function squashes the output values between 0 and 1. In mathematical representation, a large negative number passed through the sigmoid function becomes 0 and and a large positive number becomes 1.
Graph of sigmoid function
. The values of sigmoid function is high between the values of -3 and 3 but gets flatter in other regions.
Graph of sigmoid derivative
. Sigmoid function is easily differentiable and the values are dependent on x values. This means that during back propagation, we can easily use sigmoid function to update weights.
Gradient values of sigmoid
Gradient values of sigmoid range between 0 and 0.25 .
Equation of sigmoid function and its derivatives
Code for sigmoid function in python
def sigmoid(z):
return 1 / (1 + np.exp(-z))
When we write code for sigmoid, we can use this code for both forward propagation and to compute derivatives .
Problems with sigmoid function
Values obtained from sigmoid function are not zero centered.
We can easily face the issue of vanishing gradients and exploding gradients.
Let me explain you how sigmoid function face the problem of vanishing gradients and exploding gradients
Vanishing gradients problem for sigmoid function
Exploding gradients problem for sigmoid
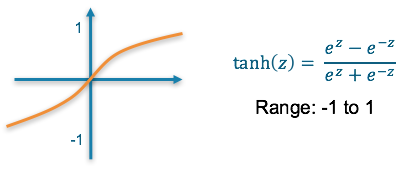
Tanh
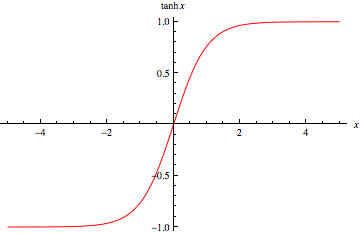
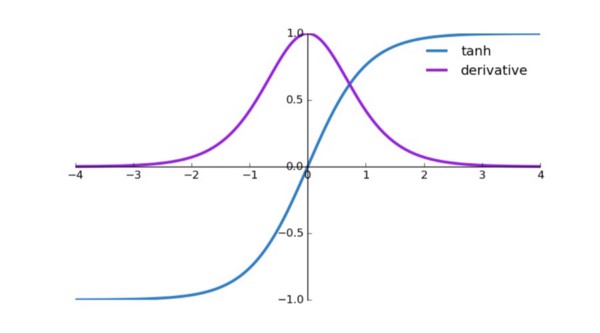
Tanh function is similar to sigmoid function. Working of tanh function is also similar to the sigmoid function but it is symmetric over the origin . It is continuous and differentiable at all points. It basically takes a real valued number and squashes values to between -1 and 1. Similar to sigmoid neuron, it saturates at large positive and negative values. The output of tanh is always zero centered. Tanh functions are preferred in hidden layers over sigmoid.
Graph of Tanh function
. Tanh function takes the real valued function and outputs the values between -1 and 1.
Graph of derivative of tanh function
.The derivative of the tanh function is steeper as compared to the sigmoid function.
. Graph of the tanh function is flat and the gradients are very low.
Equation of tanh function
Code for tanh function in python
def tanh(z):
return np.tanh(z)
Gradient values of tanh
Gradient values of tanh range between 0 and 1.
Problems with tanh function
We can easily face the issue of vanishing gradients and exploding gradients in tanh function also.
Let me explain you how Tanh function face the problem of vanishing gradients and exploding gradients
Vanishing gradients problem for tanh function
Exploding gradients problem for tanh function
ReLU
ReLU means Rectified Linear Unit. This is the mostly used activation unit in deep learning. R(x)=max(0,x) i.e., if x<0, R(x)=0 and if x≥۰,R(x)=x. It also accelerates the convergence of stochastic gradient descent as compared to sigmoid or tanh activation functions. Main advantage of using the ReLU function is, it does not activate all the neurons at the same time i.e., if the input is negative, it will convert to zero and the neuron does not get activated. This means only a few neurons are activated making the network easy for computation. It also avoids and rectifies vanishing gradient descent problem. Almost all deep learning models use ReLU activation function nowadays.
How do you say ReLU is a non-linear function ?
Linear functions are straight line functions. But, ReLU is not a straight line function because it has bend a at value zero. Hence,we can say that ReLU is a non-linear function. Please have a look at graph of ReLU function.
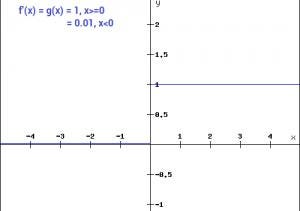
Graph for ReLU function
. If the value of x is greater than or equal to zero then the we take ReLU(x)=x.
. If the value of x is less than zero then we take ReLU(x)=0.
Graph for derivative of ReLU function
If the value of x is greater than zero, then the derivative of the ReLU(x) i.e., ReLU’(x)=1.
If the value of x is less than zero, then the derivative of the ReLU(x) i.e., ReLU’(x)=0.
Problem with ReLU function
Dead neurons
If the units are not activated initially, then during back propagation, zero gradients flow through them. Hence, neurons that already died won’t respond to the variation in the output and the weights will never get updated during back propagation. This problem is called as dead neurons problem.
Equation of derivative of ReLU function
Code for ReLU activation in python
def relu(z):
return z * (z > 0)
Leaky ReLU
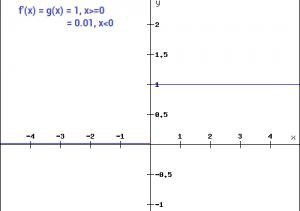
Leaky ReLU is an improved version of ReLU function. We know that in ReLU, the gradient is 0, for x<0. Here in Leaky ReLU, instead of defining the ReLU function as 0, for x<0, we define it as a multiple of small linear component of x i.e., 0.01x (Generally we take linear component as 0.01). The main advantage in Leaky ReLU is, we are just replacing horizontal line on x-axis to non-zero and non horizontal line. We are doing this to remove zero gradient. So, by removing the zero gradients, we won’t face any issue of dead neurons.
Graph of Leaky ReLU function
If the value of x is greater than zero, then the Leaky ReLU(x)=x.
If the value of x is less than zero, then the Leaky ReLU(x)=0.01*x.
Graph of derivative of Leaky ReLU function
If the value of x >0, then the derivative of Leaky ReLU(x) i.e., Leaky ReLU’(x)=1.
If the value of x <0, then the derivative of Leaky ReLU(x) i.e., Leaky ReLU’(x)=0.01.
Equation of Leaky ReLU and derivative of Leaky ReLU
Here alpha is the small linear component of x . Typically we take alpha value as 0.01 .
Code of Leaky ReLU in python
def leaky_relu(z):
return np.maximum(0.01 * z, z)
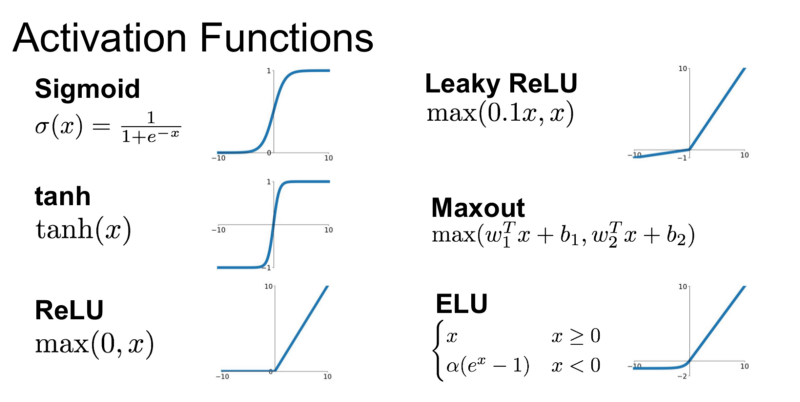
Let me keep all the graphs at one place. So, that you can easily understand the difference between them.
Graphs of activation functions
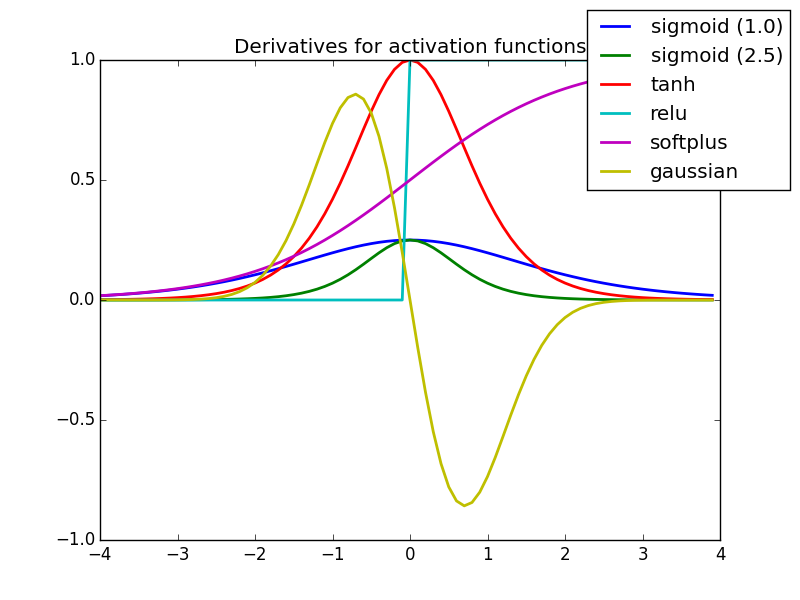
Graphs of derivative of activation functions
Some complex terms like Maxout and ELU are not covered.
Let me keep all the activation function equations and their derivatives at one place, So that you can easily catch up and rewind them easily.
How to choose the right activation function?
Depending upon the properties of the given problem, we might be able to make a choice and can make a faster convergence of the network.
Sigmoid functions work better in case of classifiers.
ReLU is general activation function and can be used in most cases.
If we encounter dead neurons in our network, then Leaky ReLU is the best choice.
As a rule of thumb, we can begin with ReLU activation function and we can move to other activation functions, if ReLU does not perform well in our network.