
آلن تورینگ می گوید:
به جای اینکه سعی در تولید برنامه ای برای شبیه سازی ذهن یک بزرگسال کنیم،چرا سعی در تولید یک برنامه با محوریت شبیه سازی ذهن یک کودک نکنیم؟
با نیروی وحشیانه پردازنده های گرافیکی و درک بهتر هوش مصنوعی، قهرمانان بازی GO را شکست می دهیم و Face ID با هر آیفون جدید همراه می شود. اما در دنیای روباتیک، آموزش روباتی که بتواند کاهو را پوست بگیرد خبر ساز می شود. حتی با وجود یک مزیت ناعادلانه مثل سرعت محاسبات، یک رایانه هنوز هم نمی تواند وظایفی را که ما انجام می دهیم را به خوبی مدیریت کند. دشواری این قضیه این است که هوش مصنوعی مثل انسان یاد نمیگیرد. ممکن است ما فقط چند مقاله دیگر با پیشرفت و یادگیری موثرتر فاصله داشته باشیم. در این مقاله، ما خط مشی جدیدی را آغاز می کنیم که این کاستی ها را برطرف می کند. ما همچنین به حوزه های تحقیقاتی مهم و چالش هایی که RL (یادگیری تقویتی) با آن روبروست ، خواهیم پرداخت.
یادگیری تقلیدی
کودکان تقلید می کنند. تقلید نقش اصلی را در یادگیری ایفا می کند. در بسیاری از روش های یادگیری تقویتی ما تجزیه و تحلیل می کنیم که با تغییر تصمیم های ما نتایج و نتایج چه تغییری خواهند کرد. این امر می تواند با درک بهتر دینامیک سیستم یا از طریق آزمون و خطای هوشمند انجام شود تا بفهمید چه تصمیماتی نتایج بهتری می دهد. با این وجود ، با موفقیت یادگیری نظارت شده در یادگیری عمیق، میتوانیم آنها را کاملاً نادیده بگیریم و تصمیمات خبره را به طور مستقیم، به سیستم آموزش دهیم.
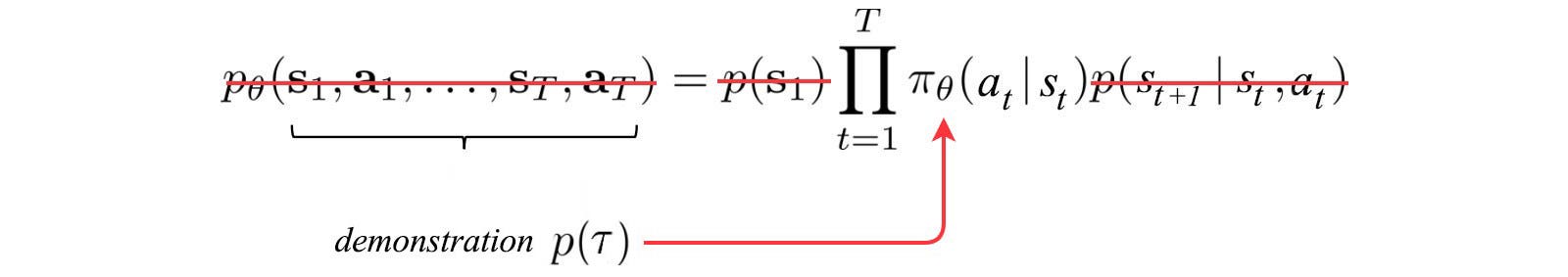
برخلاف دیگر روش های یادگیری تقویتی، ما وقت خود را برای یافتن آنچه امیدوارکننده نیست تلف نمی کنیم. ما برای پیدا کردن راه حل از اثبات استفاده می کنیم.

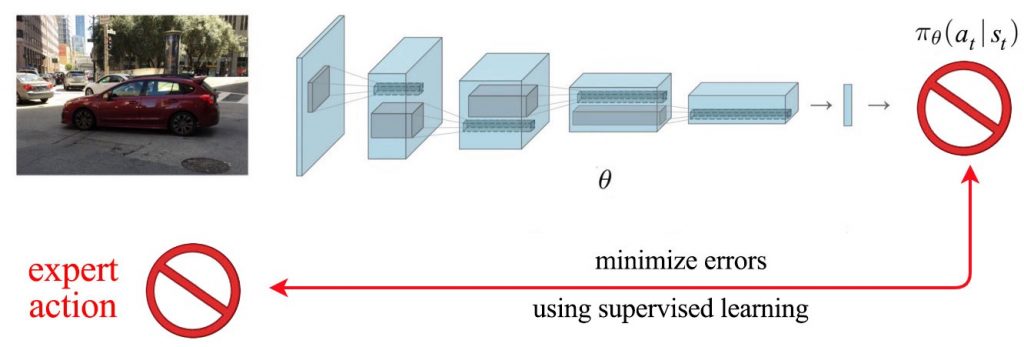
چالش
ما هیچوقت چیزی را کپی نمی کنیم. در نتیجه،مشکل ها به سرعت خود را نشان می دهند و ما را درون موقعیتی قرار می دهند که تا قبل از آن با آن مواجه نشده بودیم و هیچ نمونه ای در آن زمینه نداریم.
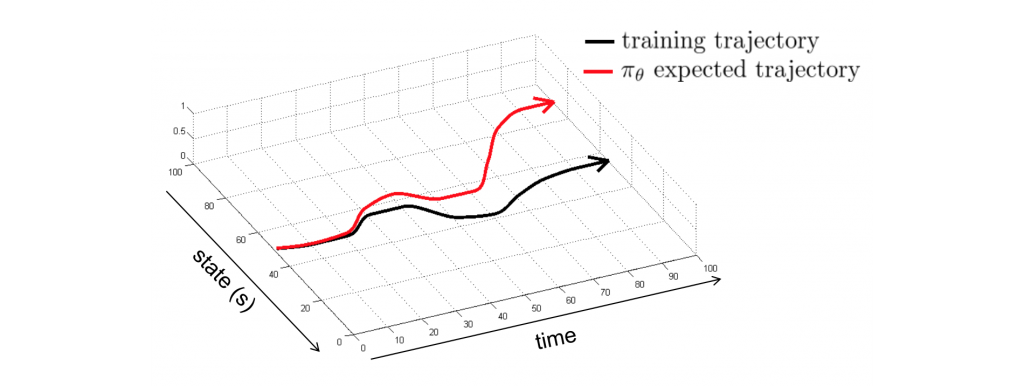
به عنوان یک انسان زمانی که اشتباه میکنیم عملیات اصلاحی را انجام می دهیم. اما یادگیری تقلیدی از تمرینات نمونه های ما آموزش می گیریند. برای پرداختن به این موضوع، می توانیم نمونه های اضافی را برای شرایط خارج از دور جمع آوری کنیم. ما راه حل را مستقر کرده و بررسی می کنیم چه چیزی را از دست داده ایم. سپس به سراغ سیستم خبره برمی گردیم تا دو مرتبه اقدامات اصلاحی را برچسب گذاری کنیم. از سوی دیگر، ما به طور عمد اختلالات کوچکی اضافه می کنیم تا مشاهده کنیم سیستم خبره چگونه عکس العمل نشان می دهند. علاوه بر این،در بعضی از کار های خاص، می توانیم راه حل هایی را برای مشکلات شناخته شده کد گذاری کنیم. فقط باید آنها را در حین آموزش مشخص کنیم.
انسان در مقابل ماشین
استفاده از اثبات های انسانی هزینه زیادی دارد و همچنین مجبور به استقاده مکرر از خبره برای پر کردن سوراخ ها هستیم. شرایطی وجود دارد که یک کامپیوتر می تواند برنامه ریزی بهتری برای دوره های اقدامات اصلاحی انجام دهد. با نمونه برداری از داده های محلی ، اطلاعات اضافی به کامپیوتر کمک می کند تا مدل محلی و مشکل را بهتر تعریف کند. این می تواند تصمیمات محلیای تولید کند که حتی بهتر از تصمیمات انسان باشد. اما این راه حل ها مشکلاتی دارند از جمله: اولا به خوبی همه مشکلات را پوشش نمیدهند، دوما در برابر تغییر شرایط آسیب پذیر نشان می دهند و در آخر نتایج با ثباتی را فراهم نمی کنند. علاوه بر این ها، تصمیمات محلی جانبدارانه گرفته می شوند.
در پاداش ممکن است اقدامات اصلاحی ما در یادگیری عمیق به ما دروغ بگوید. با تمرینات مناسب،یادگیری عمیق می تواند در استخراج الگو های مشترک و از بین بردن اختلالات در اطلاعات به خوبی عمل کند. اگر بتوانیم استراتژی آموزش را به خوبی برنامه ریزی کنیم ، می توانیم با تقلید از کنترل هایی که توسط رایانه برنامه ریزی شده است ، سیاست خوبی داشته باشیم. حتی عمل نمونه برداری فردی ممکن است تخصصی یا ناقص باشد ، از طریق یادگیری ماشین می توانیم الگوی مشترکی را برای حل آن مشکلات بیابیم.
یکی از استراتژی ها بر روی خود تمرینی یا خود آموزی بستگی دارد. بدون تعامل انسانها ، جمع آوری تعداد زیادی از نمونه ها از نظر اقتصادی امکان پذیر می باشد. با این چجم زیاد از نمونه ها، ما می توانیم قوانین اساسی در اجرای وظایف را کشف کنیم. زمانی که اهداف نهایی در دسترس ما هستند، از این دانش برای کامل کردن آنها استفاده می کنیم.
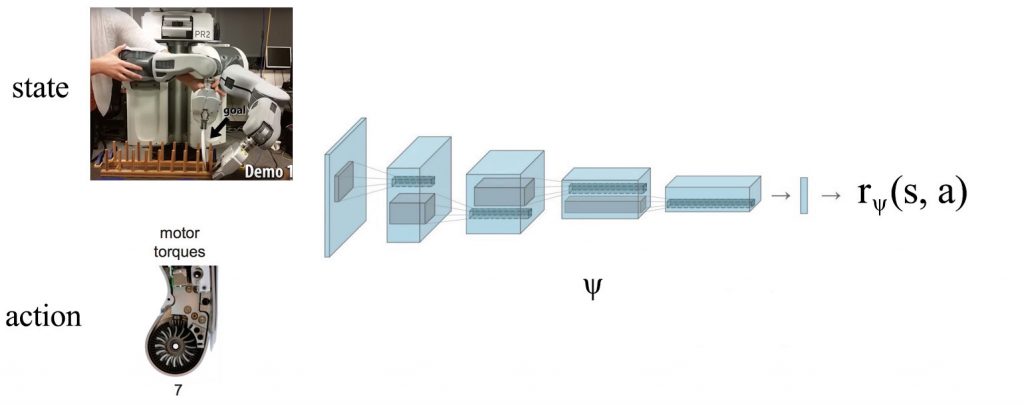
در حین آموزش،ممکن است ما به طور اختیاری هدفی را برای دستیابی در اختیار روبات قرار دهیم. این هدف لزوما به هدف نهایی ما شبییه نیست و در پاداش ممکن است برای دستیابی سخت بوده و برای کامل شدن به دخالت انسان ها در آن نیاز باشد. این قضیه پروسه خود آموزی را زیر سوال می برد و دامنه داده های جمع آوری شده را کاهش می دهد. با این حال ممکن است ما از روش خود آموزی برای مشکلات آسان تری استفاده کنیم. یا به سادگی اقدامات نیمه تصادفی را که از پیش برنامه ریزی شده هستند را به وسیله آن امتحان کنیم. قاعدتا اگر بچه ای می تواند مهارت های اساسی را یاد بگیرد پس می تواند از آن ها برای برنامه ریزی حل مشکلات پیچیده تر نیز استفاده کند. استراتژی دیگر آموزش روبات با حداقل دخالت خبره است. این شروع جستجو خط مشی اولیه را آغاز می کند ، بنابراین ما خیلی طولانی در طبیعت سرگردان نخواهیم شد. اما از همه مهمتر ، این امر اثباتهایی از خبره را را ایجاد می کند که می توانیم از آنها برای توسعه مدل در یادگیری مبتنی بر مدل یا عملکردهای پاداش در یادگیری تقویت معکوس استفاده کنیم.
یادگیری تقویتی معکوس
تنظیم اهداف برای هر پروژه ای بسیار مهم است. چون فراتر از حد بینایی ما است در پاداش نمی دانیم چگونه می توانیم آن را به دست بیاوریم و ما ممکن است تصویر درستی از هدف خود نداشته باشیم. برای مثال ما از بازی GO استفاده می کنیم.در یادگیری تقویتی ما از پاداش نهایی بازی به عنوان تنها پاسخ استفاده می کنیم.
این برای ما دشوار است که بتوانیم اطلاعات را از هم باز کنیم تا ببینیم چه دنباله ای از اقدامات برای ما سود دارد. این نتایجِ با تاخیر و کمیاب به فرآیند تصمیم گیری ما صدمه می زند. قهرمانان این بازی موقعیت میانی را به عنوان پاداش برای دستیابی قرار می دهند. نه تنها در یادگیری تقویتی بلکه در زندگی واقعی نیز، موفقیت به این بستگی دارد که اهداف خود را به چه اندازه تعریف می کنیم تا پیشرفت را به درستی اندازه بگیریم.
در بحث فنی، شکل عملکرد دستیابی به پاداش بسیار مهم است. دو عملکرد هزینه جستو جو زیر را در نظر بگیرید، شکل سمت چپ هیچ مسیری را برای جستجو به ما نمی دهد. جز زمانی که تقریبا در نقطه بهینه هستیم هیچ حرکتی هزینه را تغییر نمی دهد. در این سناریو ، هیچ روش بهینه سازی بهتر از یک جستجوی تصادفی نخواهد بود.
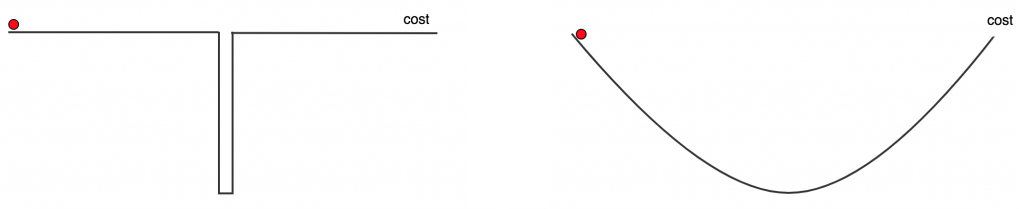
عملکرد هزینه در سمت راست بدون محو شدن یا منفجر شدن دارای شیب صاف است. این به ما به خوبی در جستجوی نقطه بهینه کمک خواهد کرد.
در بسیاری از روش های یادگیری تقویتی ما نتایج را بدون هیچ چالشی در یافت می کنیم و این سوال را از خود نمی کنیم که آیا این ما را بهتر راهنمایی می کند یا خیر. ما به طور دیوانهواری سخت کار می کنیم تا مدل یا سیاست مناسب برای رسیدن به اهداف دور دست را پیدا کنیم. از طرف دیگر ، ما برای محاسبه توابع پاداش سفارشی از ویژگی های صنایع دستی استفاده می کنیم.
با این حال ، این راه حل مقیاس نیست. به احتمال زیاد ، پس از تلاشهای جدی ، راه حل پاداش هنوز به اندازه کافی گسترده نیست تا بتواند مشکلات پیچیده را الگو بردارد. در پاداش ممکن است بار دیگر راه حل ما در دست یادگیری عمیق باشد. ما به وسیله خبره می توانیم عملکرد پاداش را یاد بگیریم.در یادگیری معکوس، ما از نتایج استفاده می کنیم تا احتمال دنباله ای از اقدامات را بدست آوریم. احتمال دنباله ای از اقدمات از طریق فرمول زیر تعریف می شود:
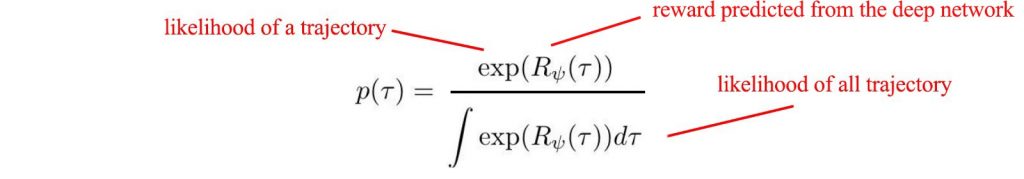
هر چه پاسخ با ارزش تر باشد، احتمال تصمیم گیری بیشتر خواهد شد.برای مدل سازی عملکرد پاداش، ما یک شبکه عمیق را در زیر آموزش می دهیم تا آن را پیش بینی کنیم. برای آموزش مدل ، از یک هدف در به حداکثر رساندن احتمال تظاهرات تخصصی استفاده می کنیم.
اما محاسبه نمره احتمال همه مسیر در مخرج فرمول زیر بسیار سخت است.
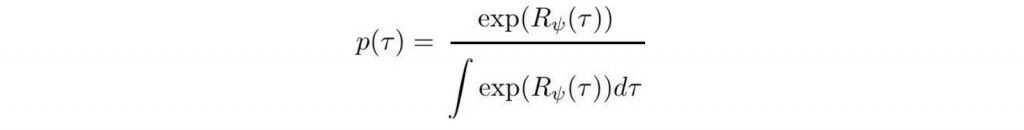
اما بیشتر مسیر دارای نتایج ناچیز است. بنابراین با استفاده از پرسودترین مسیرها می توان مخرج را نزدیک تر و آسان تر کرد.
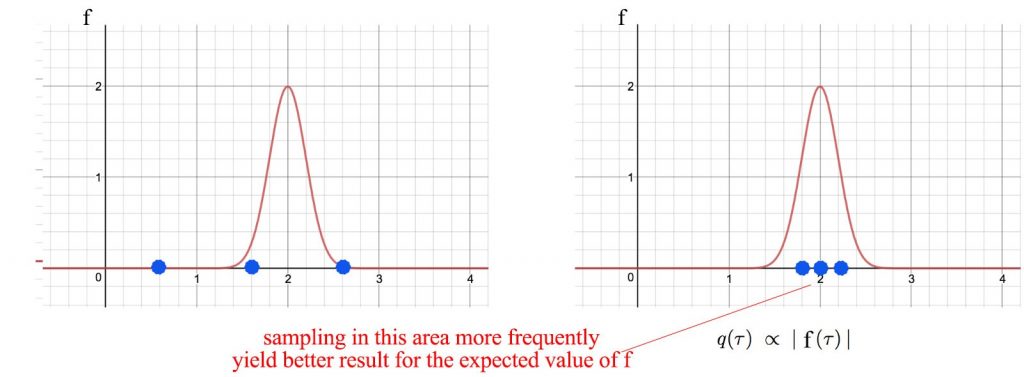
بیایید ببینیم که چگونه یک سیاست و عملکرد پاداش را در مراحل متناوب آموزش می دهیم.

طبق عکس عملکرد پاداش به دست آمده در بالا سمت چپ، ما می توانیم با استفاده از روش سیاست شیب دار، سیاست گذشته را اصلاح کنیم. سپس ما از سیاست جدید برای تولید مسیرهای جدید استفاده می کنیم و از آنها برای تقریب مخرج بهتر استفاده می کنیم. در مرحله بعد ، شیب احتمال نتایج خبره را محاسبه می کنیم.
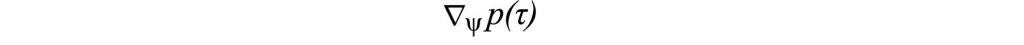
با استفاده از این شیب پاداش ، عملکرد پاداش پارامتر شده توسط ψ را به روز می کنیم تا احتمال اثبات خبره را با استفاده از صعود شیب افزایش دهیم. ما این روند را به صورت مکرر اجرا می کنیم تا مدل پاداش و سیاست در مراحل جایگزین بهبود یابد.به طور خلاصه،با عملکرد بهتر پاداش ، به سیاست بهتری می رسیم.با سیاست بهتر،شیب را با دقت بیشتری اندازه گیری می کنیم تا عملکرد را بهبود ببخشیم.
شبکه های مخالف تولید کننده(GAN)
در واقع ما می توانیم یادگیری تقویت معکوس را از دیدگاه GAN مشاهده کنیم. سیاست یا خط مشی ما مسیر ها را تولید می کند. یک تولید کننده GAN است. عملکرد پاداش به عنوان تمایزگر عمل می کند و از اندازه گیری پاداش برای تمایز بین پاسخ های خبره و مسیرهای سیاست استفاده می کند. در GAN، ما هم تمایزگر و هم تولید کننده را در مراحل متناوبی آموزش می دهیم تا تمایزگر بتواند کوچکترین فرق را زمانی که تولید کننده عملکردی را برای فریب تمایز گر تولید می کند، تشخیص بدهد. با GAN،می آموزیم که چگونه می توانیم مسیر های نزدیک به پاسخ خبره را تولید کنیم.
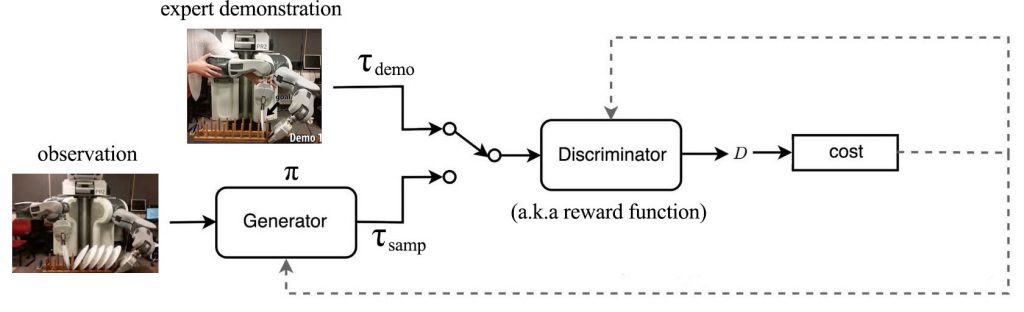
در حقیقت ، می توان از نظر ریاضی ثابت کرد که GAN معادل روش قبلی ما است اگر تابع هدف همان گونه تعریف شود که ما توضیح دادیم.
روش های تکاملی
ما می گوییم می خواهیم به موثری انسان ها یاد بگیریم. شاید ما باید این چالش را ایجاد کنیم که آیا یادگیری تقویتی باید به جای آن بر برتری سرعت محاسباتی خود تمرکز کند. روش های خط مشی شیب دار به راحتی تعداد تکرار آموزش را به ۱۰ میلیون می رسانند. به عبارت دیگر ، باید بپرسیم که این مقدار چقدر از حدس زدن تصادفی فاصله دارد.جواب نزدیک نیست اما اگر هوشمندانه حدس بزنیم می توانیم تا حدودی این شکاف را ببندیم. برای مثال می توانیم از سیاست های تصادفی شروع کنیم. ما حدس های زیادی می زنیم و نتایج جمع آوری شده را مشاهده می کنیم.ما ۲۰%از بهترین حدس ها را انتخاب می کنیم و حدس هایمان را از کل حدس ها فقط به بهترین حدس ها جهش می دهیم.حدس زدن اصلاح کردن را ادامه می دهیم.خوشبختانه می توانیم بهینه ترین سیاست را از بین این حدس های هوشمندانه پیدا کنیم. این روشها معمولاً محاسبات بسیار ساده ای دارند و ما می توانیم حدسها را به راحتی موازی سازیم.سادگی و موازی بودن با درجه بالا ، این رویکرد را در مقایسه با سایر روش های یادگیری تقویتی ، به ویژه برای گرافیک های مصنوعی ، جذاب می کند.
یادگیری تقویتی
در اینجا تصویری وجود دارد که روشهای مختلف یادگیری تقویت بر آن تأکید می کند. ما یا سایر مؤلفه ها را نادیده می گیریم یا از طریق شبیه سازی ها نتایج را نمونه برداری می کنیم.

فرمول زیر یک فرمول یکسان برای یادگیری تقلیدی، یادگیری تقویتی معکوس متمرکز و روش های تکاملی است.

همانطور که به طور مکررا ذکر شده است، روش های یادگیری تقویتی منحصر به فرد نیستند. ما اغلب آنهار را با هم ترکیب یا به هم وصل می کنیم.
قسمت دوم
در قسمت اول،ما سراغ یادگیری تقلیدی، یادگیری تقویتی معکوس و روش های تکاملی رفتیم. در قسمت دوم، ما جزئیاتی از چالش ها، راه حل های ممکن و روند یادگیری تقویتی را پوشش خواهیم داد. به طور ویژه، یاد می گیریم چگونه بهتر کشف کنیم، چگونه بهتر یاد بگیریم، چگونه از تجربیات گذشته یاد بگیریم و چگونه بهتر پیش بینی کنیم .پس با ما همراه باشید…
همچنین ببینید:
- پلاک خوان های شهر گرینزبوروی آمریکا فعلاً قرار نیست افزایش پیدا کنند
- فرماندار اوکلند از پلاک خوان ها حمایت می کند اما مخالفان در اثربخشی آن تردید دارند
- لبنان استفاده از پلاک خوان های خودکار را تایید کرد
- چالش های مدیریت کلاس با ابزار جدید تشخیص چهره هوش مصنوعی
- آیا می توان از دوربین های ترافیکی برای گرفتن رانندگان الکلی استفاده کرد؟



