

تحقیقات آی بی ام پایگاه داده های ” تنوع در چهره ها ” را در راستای پیشرفت مطالعات مربوط به دقت تشخیص در سیستم های تشخیص چهره منتشر کرده است.
تا حالا اتفاق افتاده کا با ناعدالتی با شما برخورد شود؟ پس از برخورد ناعادلانه چه حسی داشته اید؟ احتمالا حس خیلی خوبی نبوده است. بیشتر مردم در کل موافق با این موضوع هستند که دنیایی عادلانه تر، دنیایی بهتر است و محققین ما در زمینه هوش مصنوعی با آن ها هم عقیده اند. به همین دلیل است که ما از قدرت علم برای ایجاد سیستم های هوش مصنوعی ( AI ) که عادلانه تر و دقیق تر هستند استفاده می کنیم.

بسیاری از پیشرفت های اخیر ما در هوش مصنوعی ( AI ) توانایی قابل توجهی در اختیار رایانه ها برای انجام وظایفی که به طور فزاینده ای پیچیده و مهم هستند، گذاشته اند. مانند ترجمه مکالمه به زبان های دیگر برای برقراری ارتباط میان فرهنگ ها، بهبود تعاملات پیچیده بین افراد و ماشین ها و تشخیص خودکار محتوای ویدیو برای کمک به ایمنی برنامه های کاربردی.
امروزه بخش اعظم قدرت هوش مصنوعی ( AI ) ناشی از به کارگیری یادگیری عمیق ( Deep Learning ) داده محور در جهت ایجاد مدل هایی با دقت فزاینده می باشد که این کار با استفاده از داده هایی صورت می گیرد که هر روز به مقدارشان افزوده می شود. با این حال، نقطه قوت این تکنیک ها می تواند نقط ضعفی نیز برای آن ها به شمار بیاید. سیستم های هوش مصنوعی آن چه را که آموزش داده شده اند، یاد می گیرند و اگر با مجموعه داده های قوی و متنوع آموزش داده نشوند، ممکن است دقت، صحت و عدالت در این سیستم ها در معرض خطر قرار گیرند. به همین دلیل، IBM، همراه با توسعه دهندگان هوش مصنوعی ( AI ) و جامعه تحقیقاتی، باید در مورد داده هایی که ما برای آموزش استفاده می کنیم محتاط عمل کنند. آی بی ام همچنان متعهد به توسعه سیستم های هوش مصنوعی ( AI ) است تا دنیا را به جایی عادلانه تر تبدیل کند.
چالش توسعه هوش مصنوعی ( AI ) با تکنولوژی تشخیص چهره به صورت کاملا شفاف و عمیق خود را نشان داد. در ایجاد سیستم های تشخیص چهره ای که بتوانند انتظارات مربوط به دقت و برابری در این سیستم ها وجود دارد را برآوردن کنند مشکلاتی وجود دارد. همانطور که توسط جوی بوولاموینی و تیمنیت جابر در مقاله سایه های جنسیت در سال ۲۰۱۸ نشان داده شده است، سیستم های تشخیص چهره ای که کاربرد تجاری داشتند، عملکردشان در تشخیص چهره افراد مذکر با چهره روشن ( سفید پوست ) نسبت به تشخیص چهره افراد مونث با چهره تیره تر ( رنگین پوست ) بهتر بوده است. وجه اصلی مشکل، خود تکنولوژی هوش مصنوعی ( AI ) به تنهایی نیست، بلکه این است که سیستم های تشخیص چهره هوش مصنوعی ( AI ) چگونه آموزش دیده اند. به عنوان مثال، مجموعه داده های آموزشی باید به اندازه کافی بزرگ و به اندازه کافی متنوع باشند تا تکنولوژی تشخیص چهره تمام شیوه هایی را که در آن چهره ها امکان دارد متفاوت به نظر برسند، به طرز دقیقی این تفاوت ها را در موقعیت های مختلف تشخیص دهد. تصاویر باید منعکس کننده پراکندگی ویژگی ها در چهره هایی که در جهان مشاهده می کنیم باشند.
چگونه می توانیم تنوع چهره های انسانی را اندازه گیری کنیم و از صحت آن اطمینان داشته باشیم؟ از یک طرف، ما با چگونگی تغییر شکل چهره ها بر اساس سن، جنسیت و رنگ پوست آشنا هستیم و این که چگونه چهره ها در برخی از این ابعاد می توانند متفاوت باشند. بخش عمده ای از تمرکزی که بر تکنولوژی تشخیص چهره وجود دارد این است که عملکرد این تکنولوژی با این ویژگی های متنوع تا چه اندازه خوب خواهد بود. اما، همانطور که مطالعات پیشین نشان داده اند، این ویژگی ها تنها یک قطعه ای از پازل هستند و به طور کامل برای توصیف تنوع کامل چهره های انسان کافی نیستند. ابعادی مانند تقارن چهره، کنتراست صورت، حالتی که چهره در آن قرار دارد ، طول یا عرض ویژگی های چهره ( چشمان، بینی، پیشانی و غیره ) نیز مهم هستند.
در زمان حاضر، تحقیقات آی بی ام مجموعه ای از داده هایی جدید با حجم بالا و متنوع با نام “تنوع در چهره ها” ( Diversity in Faces ) را در راستای پیشرفت مطالعات مربوط به عدالت در سیستم های تشخیص چهره منتشر کرده است. این تکنولوژی که در نوع خود اولین تکنولوژی ای است که در اختیار جامعه بین الملی تحقیقاتی قرار دارد، تنوع در چهره ها ( DIF ) مجموعه داده های تفسیری از ۱ میلیون تصویر صورت انسان را فراهم می کند. با استفاده از تصاویر عمومی موجود از مجموعه داده های YFCC-100M Creative Commons، ما چهره ها را با استفاده از ده نوع طرح کدنویسی با ساختاری خوب و مستقل را از نظریات علمی موجود، خلاصه برداری کردیم. طرح های کد نویسی عمدتا شامل ابعاد عینی چهره های انسانی، از قبیل ویژگی های استخوان بندی صورت ( Craniofacial )، و همچنین نکات درونی مانند پیش بینی هایی از قبیل سن و جنس انسان است. ما اعتقاد داریم که با استخراج و انتشار این حاشیه نویسی های مربوط به طرح بندی چهره در یک مجموعه بزرگ از ۱ میلیون تصویر چهره، خواهیم توانست مطالعه ی تنوع و پوشش داده ها برای سیستم های تشخیص چهره هوش مصنوعی ( AI ) را برای اطمینان از سیستم های هوش مصنوعی ( AI ) عادلانه تر و دقیق تر تسریع کنیم. نتایجی که امروز منتشر می شوند قدم اول در راه انجام این کار است.
ما معتقدیم که مجموعه داده های تنوع در چهره ها ( DIF ) و ۱۰ طرح مربوط به کدنویسی آن، نقطه شروعی برای محققان در سراسر جهان است که در حال مطالعه فناوری تشخیص چهره هستند. ۱۰ روش کدگذاری چهره عبارتند از: استخوان بندی صورت ( به عنوان مثال طول سر، طول بینی، طول پیشانی )، نسبت چهره ( تقارن )، ویژگی های بصری ( سن، جنس )، و حالت چهره و رزولوشن به همراه برخی دیگر از روش ها. این طرح ها برخی از قوی ترین طرح هایی هستند که در ادبیات علمی مربوط به این موضوع شناسایی شده اند، که بنای محکمی را برای دانش گردآوری شده ما می سازند.
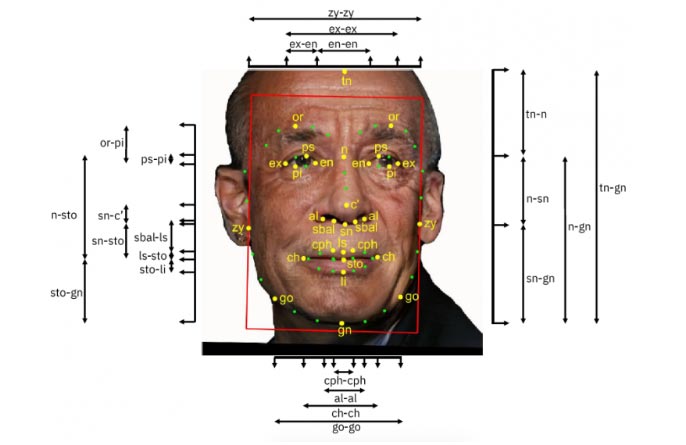
تجزیه و تحلیل اولیه ما نشان داده است که مجموعه داده های تنوع در چهره ها ( DIF ) توزیعی متعادل تر و پوششی گسترده تر از تصاویر صورت را در مقایسه با مجموعه داده های قبلی ارائه می دهد. علاوه بر این، بینش های به دست آمده از تجزیه و تحلیل آماری ده طرح اولیه مربوط به کد نویسی در مجموعه داده های تنوع در چهره ها ( DIF ) ، درک ما را از آنچه که برای مشخص کردن چهره های انسان مهم است افزایش داده و ما را قادر ساخته تا به تحقیقات مهم برای رسیدن به راه های بهبود فن آوری تشخیص چهره ادامه دهیم. این مجموعه داده امروزه بنا به درخواست جامعه پژوهشی جهانی در اختیارشان قرار می گیرد. IBM مفتخر است که که این تکنولوژی را در دسترس جامعه پژوهشی قرار دهد و هدف ما این است که به افزایش تحقیقات جمع آوری شده توسط جامعه پژوهشی IBM کمک کنیم و در ایجاد سیستم های هوش مصنوعی ( AI ) که عادلانه تر هستند مشارکت داشته باشیم. در حالی که تحقیقات IBM متعهد به مطالعه و تحقیق در مورد سیستم های تشخیص چهره عادلانه میباشند، ما اعتقاد نداریم که می توانیم این کار را به تنهایی انجام دهیم. با نتایجی که از تحقیقاتمان امروز منتشر کردیم، ما از دیگران میخواهیم تا به تحقیقات روز افزون و پیشبرد این برنامه علمی مهم کمک کنند.
برای درخواست دسترسی به دیتاست تنوع در چهره ها ( DIF ) می توانید به لینک زیر مراجعه فرمایید.
بیشتر بخوانید :
- پلاک خوان های شهر گرینزبوروی آمریکا فعلاً قرار نیست افزایش پیدا کنند
- فرماندار اوکلند از پلاک خوان ها حمایت می کند اما مخالفان در اثربخشی آن تردید دارند
- لبنان استفاده از پلاک خوان های خودکار را تایید کرد
- چالش های مدیریت کلاس با ابزار جدید تشخیص چهره هوش مصنوعی
- آیا می توان از دوربین های ترافیکی برای گرفتن رانندگان الکلی استفاده کرد؟



