

کارکتر های انسان نما، یک حوزه ی مهم از انیمیشن کامپیوتری را به نمایش می گذارند. این کارکتر ها اجزای بسیار مهم و حیاتی بسیاری از برنامه ها مانند کارتون ها، بازی های کامپیوتری، جلوه های ویژه سینمایی، واقعیت مجازی، اصطلاحات هنری و غیره هستند. با این حال، تولید کارکتر انیمیشنی معمولا از طریق تعدادی از مراحل مشخص تولید انجام می شود و همینطور یک وظیفه دشوار است.
کار قبلی
چنین کار فشرده ای، یک تنگنا در تمام مراحل ساخت یک انیمیشن کامپیوتری به وجود می آورد. در گذشته، تلاش های زیادی برای غلبه بر این مشکل صورت گرفته است تا این وظیفه توسط دستگاه های اتوماتیک پشتیبانی شود و یا حتی کاملا خودکار شود.
تعداد زیادی از رویکرد های پیشنهادی درگذشته وقتی به تولید ربات ها و کنترل کننده های حرکت طبیعی که شخصیت های مجازی را قادر می سازد تا مهارت های پیچیده در محیط های شبیه سازه شده ی بدنی را اجرا کنند، می رسیدند، به مشکل بر می خوردند. تلاش ها و رویکردهای اولیه بیشتر روی فهمیدن فیزیک و بیومکانیک متمرکز شده اند و تلاش بر این بود که الگوهای حرکتی به شخصیت های مجازی، الگوسازی و تکثیر شوند. با این حال، رویکردهای داده محور بجز تعداد کمی از استثنا ها، بر پایه ی داده ضبط حرکت (Motion Capture) استوار هستند که غالبا نیازمند ابزار دقیق و پیش پردازش سنگین هستند.
ایده ی های نوین
اخیرا، تحقیقی که محققان هوش مصنوعی Berkeley در دانشگاه کالیفرنیا انجام دادند، ایده ی جدیدی با موضوع رویکرد تقویتی یادگیری برای یادگیری حرکت کارکتر ها از ویدیوها است، پیشنهاد کرده اند.
با ترکیب برآورد حرکت از ویدیو ها و یادگیری تقویتی عمیق، شیوه آن ها قادر به ترکیب یک کنترل کننده که از یک ویدیوی تک چشمی (بدون دوربین اضافه برای تشخیص عمق) به عنوان ورودی استفاده می کند، می باشد. به علاوه، شیوه ی پیشنهادی قادر به پیش بینی پتانسیل حرکت های بشر با استفاده از تصاویر ثابت می باشد که توسط شبیه سازی رو به جلوی، کنترل کننده های آموزش دیده مقدماتی از حالت ناظر انجام می شود.
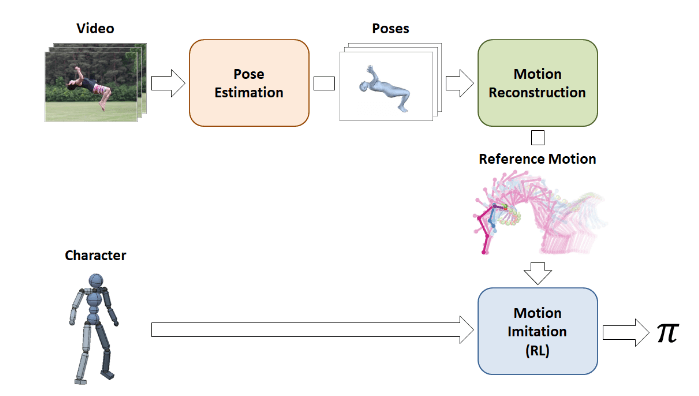
شیوه
محققان یک چارچوب پیشنهاد داده اند که توسط مدل شخصیت شبیه سازی شده با استفاده از یک ویدیوی یک چشمی و حرکت تقلید شده را خروجی می دهد. رویکرد کلی بر اساس تخمین حالت در فریم های ویدیو است که بعد برای بازسازی حرکت و تقلید حرکت برای رسیدن به هدف نهایی استفاده می شود.
نخست، ویدیوی ورودی توسط مرحله تخمین حالت پردازش می شود، جایی که تخمین زننده های آموزش دیده ی ۲ بعدی و ۳ بعدی برای استخراج (تخمین) حالت انجام شده توسط بازیگر در هر فریم، استفاده می شوند. سپس، دسته ای از حالت های پیش بینی شده، مرحله بازسازی حرکت را ادامه می دهند، که در آن مسیر حرکت مرجع بهینه سازی شده است تا با پیش بینی های هر دو حالت ۲ بعدی و سه بعدی سازگار باشد که استحکام موضعی در میان فریم ها ایجاد می کند. مرجع حرکت در مرحله تقلید حرکت استفاده می شود، که در آن یک قانون کنترل آموزش دیده تا شخصیت را قادر سازد تا حرکت مرجع را در یک محیط شبیه سازی شده فیزیکی تولید کند.
مرحله تخمین حالت
اولین ماژول در پایپ لاین، واحد تخمین حالت است. در این مرحله، هدف، تخمین حالت بازیگر از تک عکس ثابت به عنوان مثال از هر فریم ویدیو است. تعدادی چالش وجود دارند که باید در این مرحله پاسخ داده شوند تا تخمین حالت صحیح و دقیق به دست آید. اولا، تنوع در گرایش بدنی در بین بازیگران مختلف که یک حرکت یکسان را انجام می دهند، بسیار بالاست. دوما، تخمین حالت در هر فریم بدون وابستگی به فریم های قبلی یا بعدی، بدون در نظر گرفتن ثبات زمانی انجام می شود.
برای پاسخ به هر دوی این موضوعات، محققان پیشنهاد دادند تا یک دسته از شیوه هایی که از قبل وجود داشته و ثابت شده بودند، برای تخمین حالت استفاده شوند. همراه با آن، آن ها از یک تکنیک ساده افزایش داده ها استفاده می کنند تا پیش بینی حالت در دامنه حرکات آکروباتیک را بهبود بخشند.
آن ها یک دسته از تخمین زننده ها را روی مجموعه داده های افزایش یافته آموزش می دهند و تخمین حالت های ۲ بعدی و ۳ بعدی را برای هر فریم به دست آورند که مسیر های حرکتی ۲ بعدی و ۳ بعدی را به ترتیب نشان می دهند.

مرحله بازسازی حرکت
در مرحله بازسازی حرکت، پیش بینی های مستقل از تخمین زننده های حالت، یکی می شوند تا حرکت مرجع پایانی را به وجود آورند. هدف نهایی که محققان در این مرحله برایش برنامه ریزی کرده اند، بهبود بخشیدن کیفیت حرکت های مرجع با حذف کردن خطاها و حرکت های ساختگی که اغلب به عنوان رفتارهای غیرفیزیکی جلوه می کنند، می باشد. طبق تحقیق محققان، این حرکت های ساختگی به علت پیش بینی های ناسازگار و در سراسر چارچوب های مجاور ظاهر می شوند.
دوباره، در این مرحله یک تکنیک بهینه سازی درخواست شده است، بهینه سازی برای حالت مسیر ۳ بعدی رایج برای تخمین زننده های حالت است، در حالی که همزمان اجرای ثبات زمانی، ما بین چارچوب های پشت سر هم، صورت می گیرد. بهینه سازی در فضای نهفته انجام می شود، با استفاده از تخمین زننده های حالت که در حال اعمال نفوذ در معماری رمزنگار – رمزگشا می باشند.
مرحله تقلید حرکت
در آخرین مرحله، یادگیری تقویتی عمیق برای رسیدن به هدف نهایی اجرا می شود.از دیدگاه یادگیری ماشین، اینجا هدف یاد گرفتن یک قانون است که کارکتر را قادر می سازد تا مهارت نشان داده شده در ویدیوی شبیه سازی شده را باز سازیکند.حرکت مرجع که از قبل استخراج شده است، برای تعریف هدف تقلید استفاده می شود و یک قانون برای تقلید حرکت داده شده، آموزش دیده شده است.
عملکرد پاداش دهی برای تحریک کارکتر به دنبال کردن جهت گیری مشترک از حرکت مرجع طراحی شده است. در واقع، تفاوت های چهارگانه ی چرخش های مفصل در بین چرخش های مفصل شخصیت و چرخش های مفصل استخراج شده از حرکت مرجع، محاسبه شده است.
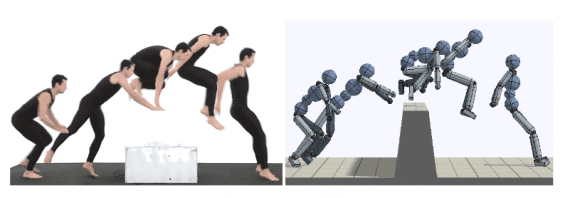
نتایج
برای نشان دادن چارچوب پیشنهادی و همینطور سنجیدن شیوه پیشنهادی، محققان یک کارکتر شبیه به انسان ۳ بعدی و یک ربات اطلس شبیه سازی شده را به کار گرفتند. یک سنجش کیفی با استفاده از مقایسه تصاویر فوری گرفته شده از شخصیت های شبیه سازی شده با نمایش های ویدیویی اصلی صورت می گیرد.همه ی کلیپ های ویدیویی از یوتیوب جمع آوری شده و آن ها اجرای حرکات آکروباتیک مختلف توسط انسان را نمایش می دهند. همانطور که روی کاغذ اشاره شده است، از آنجا که تعیین کمیت تفاوت های بین حرکت بازیگر در ویدیو و کارکتر شبیه سازی شده، یک چالش دشوار است، اجرا با نگاه به حرکت مرجع استخراج شده، سنجیده می شود. تصاویر زیر نشان دهنده عکس های فوری روی هم افتاده از یک ویدیوی واقعی و کارکتر های شبیه سازی شده برای سنجش کیفی است.
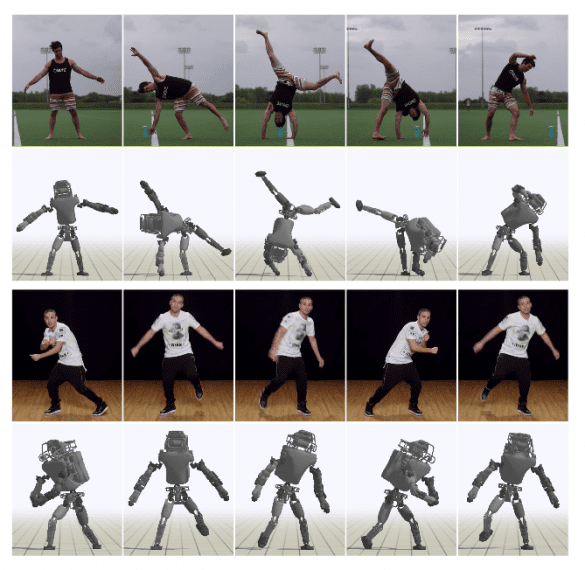



نتیجه گیری ها
شیوه پیشنهادی برای ساخت انیمیشن داده محور، تعداد زیادی از ویدیو کلیپ های عمومی از وب را تحت تاثیر و نفوذ قرار می دهد تا مهارت های حرکت تمام قد را یاد بگیرد و همینطور سهم قابل توجهی را نمایش می دهد. چارچوب پیشنهادی پتانسیل ترکیب چندگانه و تکنیک های مختلف برای ساختن چارچوب و رسیدن به هدف اختصاصی را نشان می دهد.همینطور مزیت بزرگی از طراحی ماژولار با توجه به پیشرفت های جدید وجود دارد که مربوط به مراحل مختلفی از پاپ لاین است که می تواند در مراحل بعدی گنجانده شود تا به طور کلی اثربخشی چارچوب، بهبود یابد.
بیشتر بخوانید :
- هوش مصنوعی مولد تهدیدات جدیدی برای امنیت سایبری ایجاد می کند
- فناوری تشخیص پلاک خودرو چگونه جامعه را هوشمندتر می کند
- گوگل ساختار سازمانی خود را جهت تمرکز بر هوش مصنوعی اصلاح می کند
- پلاک خوان های شهر گرینزبوروی آمریکا فعلاً قرار نیست افزایش پیدا کنند
- فرماندار اوکلند از پلاک خوان ها حمایت می کند اما مخالفان در اثربخشی آن تردید دارند



