
اگر شما یادگیری ماشین را برای رسیدن به یک شغل عالی، در حوزه علوم داده، یاد می گیرید، پس نباید یادگیری این ۱۱ الگوریتم برتر یادگیری ماشین را از دست بدهید.
در اینجا ابتدا به الگوریتم های یادگیری نظارت شده خواهیم پرداخت و سپس در مورد روش های یادگیری بدون نظارت بحث خواهیم کرد. تمرکز ما بر روی رایج ترین الگوریتم های یادگیری ماشین خواهد بود، در حالی که الگوریتم های یادگیری ماشین بسیار زیادی وجود دارد.
این الگوریتم های یادگیری ماشین برای توسعه مدلسازی پیش بینی و برای انجام کلاسه بندی و پیش بینی، هم در زمینه های نظارت شده و هم بدون نظارت، بسیار ضروری و مفید هستند.
الگوریتم های برتر یادگیری ماشین
در زیر برخی از بهترین الگوریتم های یادگیری ماشین آورده شده است :
- رگرسیون خطی
- رگرسیون لجستیک
- درختان تصمیم گیری
- بیز ساده
- شبکه های عصبی مصنوعی
- خوشه بندی K-mean
- تشخیص ناهنجاری
- مدل مخلوط گوسی (GMM)
- تحلیل مؤلفه های اصلی (PCA)
- k نزدیک ترین همسایگی KNN))
- ماشین های بردار پشتیبان (SVM)
۱- رگرسیون خطی
روشی برای اندازه گیری رابطه بین دو متغیر پیوسته، به عنوان رگرسیون خطی شناخته می شود. که شامل دو نوع متغیر است:
- متغیر مستقل : ” x “
- متغیر وابسته : ” y “
در یک رگرسیون خطی ساده، مقدار پیش بینی کننده، یک مقدار مستقل است که به هیچ متغیری، وابستگی ندارد. رابطه بین x و y به صورت زیر است:
y = mx + c
که m شیب و c عرض از مبدا است.
براساس این معادله، می توانیم خروجی را که از طریق رابطه بین متغیر وابسته و متغیر مستقل نشان داده شده ، محاسبه کنیم.
نحوه پیش بینی امید به زندگی با استفاده از رگرسیون را بیاموزید.
۲- رگرسیون لجستیک
این رایج ترین الگوریتم یادگیری ماشین برای کلاسه بندی دودویی ( باینری ) نقاط داده است. با کمک رگرسیون لجستیک، یک کلاسه بندی قطعی بدست می آوریم که خروجی آن متعلق به یکی از دو کلاس است. به عنوان مثال پیش بینی اینکه آیا قیمت نفت افزایش خواهد یافت یا نه، براساس چندین متغیر پیش بینی کننده، نمونه ای از رگرسیون لجستیک است.
رگرسیون لجستیک دارای دو مؤلفه است – فرضیه و منحنی Sigmoid. براساس فرضیه، می توان احتمال وقوع رویداد را به دست آورد. سپس داده های بدست آمده از این فرضیه در تابع لگاریتم قرار می گیرند که منحنی S شکلی به نام ” Sigmoid ” را تشکیل می دهد. از طریق این تابع لگاریتم می توان دسته ای را تعیین کرد که داده های خروجی به آن تعلق دارد.
منحنی سیگموئید S شکل، به صورت زیر است :
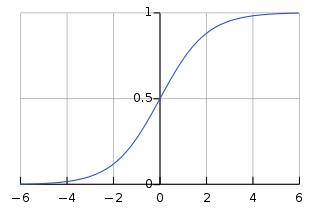
نمودار ایجادشده فوق، نتیجه معادله لجستیک زیر است –
۱/ (۱ + e^-x)
در معادله فوق ، e پایه لگاریتم طبیعی و منحنی S شکلی است که بین ۰ و ۱ بدست می آوریم. ما معادله رگرسیون لجستیک را به صورت زیر می نویسیم:
y = e^(b0 + b1*x) / (1 + e^(b0 + b1*x))
b0 و b1 دو ضریب ورودی x هستند. ما این ضرایب را با استفاده از تابع حداکثر احتمال (Maximum Likelihood) تخمین می زنیم.
۳- درختان تصمیم گیری
درختان تصمیم گیری پیش بینی و همچنین کلاسه بندی را آسان می کنند. با استفاده از درخت های تصمیم گیری، فرد می تواند با یک مجموعه داده ورودی مشخص ، تصمیم گیری کند. بگذارید درختان تصمیم گیری را با مثال زیر درک کنیم :
بیایید فرض کنیم که شما می خواهید برای خرید شامپو به بازار بروید. اول بررسی می کنید که آیا واقعا به شامپو نیاز دارید؟ اگر شامپو تمام کرده باشید، مجبورید آن را از بازار خریداری کنید. علاوه بر این، شما به بیرون نگاه می کنید و آب و هوا را ارزیابی خواهید کرد. یعنی اگر باران ببارد، شما نخواهید رفت و اگر اینطور نباشد، شما خواهید رفت. می توانیم این مثال را به طور شهودی، با تصویرسازی زیر تجسم کنیم.
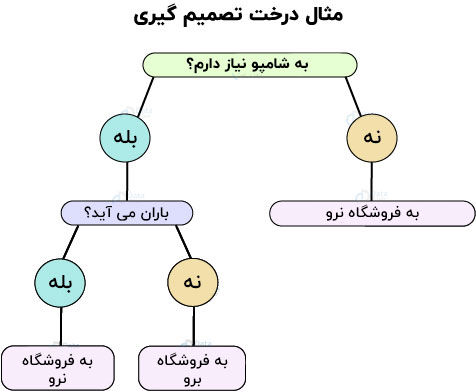
با همان اصول، ما می توانیم یک درخت سلسله مراتبی بسازیم تا خروجی خود را از طریق چندین تصمیم گیری بدست آوریم. دو روش برای ساختن یک درخت تصمیم وجود دارد – القاء و هرس. در القا، ما درخت تصمیم گیری را می سازیم و در هرس، درخت را با حذف چندین پیچیدگی، ساده می کنیم.
۴- بیز ساده
بیز ساده دسته ای از کلاسه بند های احتمال شرطی است که مبتنی بر قضیه Bayes است. آن ها ویژگی ها را مستقل فرض می کنند.
فرمول قضیه بیز یک روش استاندارد برای محاسبه احتمال پسینی P(c|x)، از P(c)، P(x)، و P(x|c) ارائه می دهد. در کلاسه بند بیز ساده، این فرض وجود دارد که تاثیر مقادیر پیش بینی کننده در یک کلاس معین (c) مستقل از سایر مقادیر پیش بینی کننده است.

قضیه بیز دارای مزایای زیادی است. آن ها به راحتی قابل پیاده سازی هستند. علاوه بر این، بیز ساده، به تعداد کمی داده آموزشی نیاز دارد و نتایج آن ها عموما دقیق هستند.
با قضیه بیز و الگوریتم بیز ساده و نحوه ی کد نویسی آن بیشتر آشنا شوید.
۵- شبکه های عصبی مصنوعی
شبکه های عصبی مصنوعی ، اساس کار نورون ها در سیستم عصبی ما را شبیه سازی می کنند. آن ها شامل نورون هایی هستند که به عنوان واحد های انباشته شده در لایه ها عمل می کنند که اطلاعات را از لایه ورودی به لایه خروجی نهایی منتقل می کنند. این شبکه های عصبی یک لایه ورودی، یک یا چند لایه پنهان و یک لایه خروجی نهایی دارند. این شبکه ها به صورت شبکه عصبی تک لایه ای (Perceptron) یا یک شبکه عصبی چند لایه ای وجود دارند.
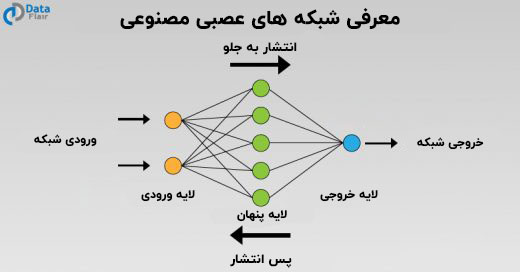
در این نمودار، یک لایه ورودی وجود دارد که ورودی را که در قالب یک خروجی است، می گیرد. پس از آن ورودی به لایه پنهان انتقال داده می شود که چندین عملیات ریاضی برای انجام محاسبات و رسیدن به خروجی مورد نظر انجام می دهد. برای مثال، با توجه به تصویری از گربه ها و سگ ها، لایه های پنهان، حداکثر احتمال دسته ای را که تصویر ما به آن تعلق دارد ، محاسبه می کنند. این مثالی از کلاسه بندی باینری است که در آن ، برای گربه یا سگ، جایگاه مناسب تعیین می شود.
آشنایی بیشتر با شبکه های عصبی و پیاده سازی آن ها
۷- خوشه بندی K-mean
خوشه بندی K-mean ، یک الگوریتم یادگیری ماشین تکرارشونده است که جداسازی داده های متشکل از n مقدار را به k زیرگروه انجام می دهد. هر یک از این n مقدار با نزدیکترین میانگین، به خوشه k تعلق دارد.
ما با استفاده از دسته ای از موارد، گروه را به چند زیرگروه تقسیم می کنیم. زیرگروه ها پایه مشابهی دارند که فاصله هر نقطه داده در زیرگروه ، مرتبط با مرکز ثقل آن ها است. این رایج ترین شکل الگوریتم یادگیری ماشین بدون نظارت است زیرا درک و پیاده سازی آن بسیار آسان است.
هدف اصلی الگوریتم خوشه بندی K – mean ، کاهش فاصله اقلیدسی به کمترین مقدار آن است. این فاصله واریانس درون خوشه ای است که ما با استفاده از تابع مربع خطای زیر به حداقل می رسانیم.
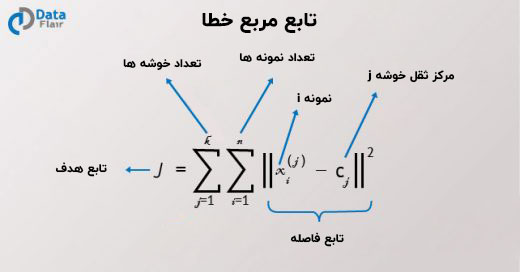
در اینجا، J تابع هدف مرکز ثقل خوشه مورد نیاز است. k خوشه وجود دارد و n تعداد نمونه ها در آن ها است. c مرکز ثقل وجود دارد و j تعداد خوشه ها است. ما فاصله اقلیدسی را از نقطه داده x مشخص می کنیم. حال بیایید نگاهی به برخی از الگوریتم های مهم خوشه بندی K – means بیندازیم :
- در مرحله اول ، مقداردهی اولیه کرده و k نقطه را انتخاب می کنیم. این k نقطه، میانگین ها را مشخص می کند.
- با استفاده از فاصله اقلیدسی، نقاط داده ای که به مرکز خوشه نزدیک تر هستند را پیدا می کنیم.
- سپس به محاسبه میانگین تمام نقاطی که به ما در یافتن مرکز ثقل کمک می کنند ، می پردازیم.
- ما تا زمانی که تمام نقاط را به خوشه مناسب اختصاص دهیم، مراحل ۱، ۲ و ۳ را تکرار می کنیم.
۷- تشخیص ناهنجاری
در تشخیص ناهنجاری، از یک تکنیک برای شناسایی الگوهای غیرعادی که مشابه الگوی عمومی هستند استفاده می کنیم. این الگوهای غیرعادی یا نقاط داده به عنوان نقاط پرت (outlier) شناخته می شوند. تشخیص این نقاط پرت، یک هدف اساسی برای بسیاری از مشاغل است که نیازمند تشخیص نفوذ، تشخیص تقلب ، پایش سیستم بهداشت و نیز تشخیص خطا در محیط های عملیاتی هستند.
Outlier یک پدیده نادر است. در واقع یک مشاهده ی بسیار متفاوت است که می تواند ناشی از برخی تغییرات در اندازه گیری یا صرفا شکلی از خطا باشد.
۸- مدل مخلوط گوسی
برای نشان دادن یک زیرجمعیت با توزیع نرمال، بین کل جمعیت، از مدل مخلوط گوسی استفاده می شود. این مدل به داده های مرتبط با زیرجمعیت نیازی ندارد بنابراین، این مدل قادر به یادگیری خودکار زیرجمعیت ها است. با توجه به اینکه تخصیص جمعیت مشخص نیست ، مدل مخلوط گوسی تحت یادگیری بدون نظارت قرار می گیرد.
به عنوان مثال ، فرض کنید که شما باید مدلی از داده های قد انسان ایجاد کنید. میانگین قد مردان ۱٫۷۶ متر و برای زنان ۱٫۶۴ است. ما فقط از داده های قد آگاه هستیم و و نه تعیین جنسیت. این توزیع از مجموع دو توزیع مقیاس بندی شده و دو توزیع نرمال انتقالی تبعیت می کند. ما این فرض را با کمک مدل مخلوط گوسی یا GMM بدست می آوریم. GMM می تواند مولفه های متعددی داشته باشد.
با استفاده از GMM می توانیم ویژگی های مهمی را از داده های گفتار استخراج کنیم ، همچنین می توانیم در مواردی که تعدادی مولفه های مخلوط دارند و همچنین وسایلی که برای پیش بینی مکان اشیاء در یک توالی ویدیویی هستند، ردیابی اشیاء را نیز انجام دهیم.
۹- آنالیز مؤلفه اصلی
کاهش ابعاد یکی از مهم ترین مفاهیم یادگیری ماشین است. یک داده می تواند چندین بُعد داشته باشد. فرض کنید این ابعاد n باشد. به عنوان مثال ، فرض کنید یک متخصص داده بر روی داده های مالی کار می کند که شامل امتیاز اعتبار ، اطلاعات شخصی ، حقوق پرسنل و موارد دیگر می باشد. برای درک برچسب های قابل توجهی که در مدل ما نقش دارند، از کاهش ابعاد استفاده می کنیم. PCA یکی از رایج ترین الگوریتم ها برای کاهش ابعاد می باشد.
با استفاده از PCA می توان، ضمن حفظ ویژگی های مهم مدل ، تعداد ابعاد را کاهش داد. PCA ها بر اساس تعداد ابعاد ساخته شده اند و هر PCA عمود بر دیگری است. حاصلضرب نقطه ای همه ی PCA های متعامد، صفر است.
آشنایی بیشتر با کاهش ابعاد با روش تحلیل مولفه های اصلی ( PCA )
۱۰- KNN
KNN یکی از الگوریتم های یادگیری ماشین است که ما برای داده کاوی و همچنین یادگیری ماشین استفاده می کنیم. این طبقه بند، بر اساس داده های مشابه ، الگوهای موجود در آن را آموزش می دهد. این یک الگوریتم یادگیری غیر پارامتری و یک الگوریتم یادگیری کند (Lazy) است. منظور ما از غیرپارامتری این است که فرض توزیع اصولی داده ها معتبر نیست. در بارگذاری تنبل ، نیازی به آموزش نقاط داده برای تولید مدل ها نیست.
داده های آموزش در مرحله تست استفاده می شود و باعث می شود مرحله تست نسبت به مرحله آموزش کندتر و پرهزینه تر باشد.
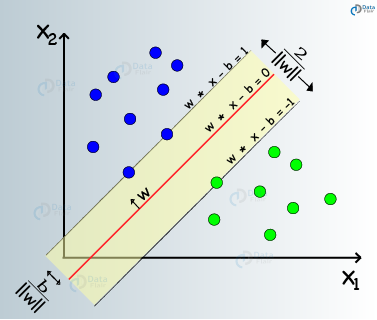
۱۱- ماشین های بردار پشتیبان(SVM)
ماشین های بردار پشتیبان نوعی از الگوریتم های یادگیری ماشین نظارت شده هستند که مدل سازی برای تجزیه و تحلیل داده ها از طریق رگرسیون و کلاسه بندی را تسهیل می کنند. SVM ها عمدتا برای کلاسه بندی استفاده می شوند. در SVM، ما داده های خود را در یک فضای n بعدی ترسیم می کنیم. مقدار هر ویژگی در SVM همان مقدار مختصات خاص است. سپس ، ما به دنبال پیدا کردن یک ابرصفحه ایده آل برای تمایز بین دو کلاس هستیم.
بردارهای پشتیبان ، نماینده مختصات مشاهده انفردای هستند. بنابراین، این یک روش مرزی است که ما برای جدا کردن دو کلاس استفاده می کنیم.
نتیجه گیری
در این مقاله ، ما به تعدادی از الگوریتم های یادگیری ماشین که در صنعت علوم داده ضروری هستند، پرداختیم. ما ترکیبی از الگوریتم های یادگیری نظارت شده و بدون نظارت که برای پیاده سازی مدل های یادگیری ماشین کاملا ضروری هستند را مطالعه کردیم. بنابراین ، اکنون شما آماده استفاده از این مفاهیم الگوریتم یادگیری ماشین در کار بعدی علوم داده خود هستید.
امیدوارم که این مقاله الگوریتم یادگیری ماشین را دوست داشته باشید. نظرات خود را در بخش نظرات زیر به اشتراک بگذارید.
بیشتر بخوانید :
- هوش مصنوعی مولد تهدیدات جدیدی برای امنیت سایبری ایجاد می کند
- فناوری تشخیص پلاک خودرو چگونه جامعه را هوشمندتر می کند
- گوگل ساختار سازمانی خود را جهت تمرکز بر هوش مصنوعی اصلاح می کند
- پلاک خوان های شهر گرینزبوروی آمریکا فعلاً قرار نیست افزایش پیدا کنند
- فرماندار اوکلند از پلاک خوان ها حمایت می کند اما مخالفان در اثربخشی آن تردید دارند



