
در این مقاله، به یادگیری برخی از الگوریتم های مهم کلاسه بندی یادگیری ماشین خواهیم پرداخت. ما الگوریتم های مختلف را بر اساس نحوه گرفتن داده ها، مورد بحث قرار می دهیم، یعنی الگوریتم های کلاسه بندی که می توانند داده های بزرگ ورودی بگیرند و آن الگوریتم هایی را که قادر به گرفتن اطلاعات بزرگ ورودی نیستند.
صبر کنید! توصیه می کنیم ابتدا انواع الگوریتم های یادگیری ماشین را بررسی کنید.
الگوریتم های کلاسه بندی یادگیری ماشین
کلاسه بندی یکی از مهم ترین جنبه های یادگیری نظارت شده است. در این مقاله، ما در مورد الگوریتم های مختلف کلاسه بندی مانند رگرسیون لجستیک ، بیز ساده ، درخت های تصمیم گیری ، جنگل های تصادفی و بسیاری دیگر بحث خواهیم کرد. ما هر یک از ویژگی های الگوریتم های کلاسه بندی و نحوه کارشان را مرور می کنیم.
۱- الگوریتم رگرسیون لجستیک
ما برای کلاسه بندی باینری نقاط داده، از رگرسیون لجستیک استفاده می کنیم. کلاسه بندی گسسته را به گونه ای انجام می دهیم که خروجی، متعلق به یکی از دو کلاس (۰ یا ۱ ) باشد. به عنوان مثال، می توانیم براساس شرایط آب و هوایی فعلی، پیش بینی کنیم که آیا امروز باران خواهد بارید یا نه.
دو مورد از بخش های مهم رگرسیون لجستیک، فرضیه و منحنی Sigmoid هستند. با کمک فرضیه، می توانیم احتمال رویداد را به دست آوریم. داده های حاصل از این فرضیه می توانند در تابع لگاریتم قرار بگیرند که منحنی S شکلی به نام” Sigmoid ” ایجاد می کنند. با استفاده از این تابع لگاریتم، می توانیم طبقه کلاس را بهتر پیش بینی کنیم.
می توانیم Sigmoid را به صورت زیر نشان دهیم:
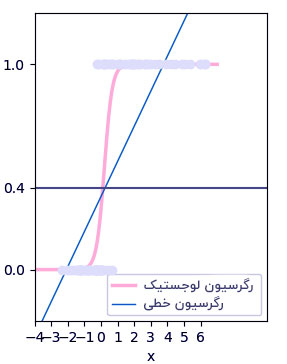
نمودار تولید شده توسط تابع لجستیک زیر بدست آمده:
۱/ (۱+ e ^ -x)
‘e’ در معادله فوق، منحنی S شکل را نمایش می دهد که مقادیر بین ۰ تا ۱ دارد. معادله رگرسیون لجستیک را به شرح زیر می نویسیم:
y = e ^ (b0 + b1 * x) / (1 + e ^ (b0 + b1 * x))
در معادله فوق ، b0 و b1 دو ضرایب x ورودی هستند. این دو ضریب را با استفاده از ” برآورد درست نمایی بیشینه ” تخمین می زنیم.
۲- الگوریتم بیز ساده
بیز ساده یکی از الگوریتم های قدرتمند یادگیری ماشین است که برای کلاسه بندی استفاده می شود. بیز ساده یک بسط از قضیه بیز است که در آن هر ویژگی مستقل فرض می شود. این روش برای کار های مختلفی از قبیل فیلترینگ اسپم و حوزه های دیگر کلاسه بندی متن استفاده می شود.
الگوریتم بیزساده برای موارد زیر قابل استفاده است:
- بیز ساده، روشی آسان و سریع برای پیش بینی کلاس مجموعه داده هاست. با استفاده از آن، می توان یک پیش بینی چند کلاسه انجام داد.
- هنگامی که فرض استقلال برقرار باشد، بیز ساده، بسیار قدرتمندتر از الگوریتم های دیگر مانند رگرسیون لجستیک است. علاوه بر این، به داده های آموزشی کمتری نیاز خواهید داشت.
با این حال، بیز ساده دارای اشکالات زیر می باشد:
- اگر متغیر گسسته، متعلق به گروهی باشد که در مجموعه آموزشی مورد بررسی قرار نگرفته باشد، آنگاه مدل، احتمال ۰ را به آن خواهد داد که مانع از پیش بینی اش می شود.
- بیز ساده فرض می کند ویژگی هایش مستقل از هم هستند. در دنیای واقعی ، جمع آوری داده هایی که ویژگی های کاملاً مستقل داشته باشند، کار دشواری است.
در مورد نظریه بیز ساده و پیاده سازی آن در پایتون بیشتر بدانید.
۳- الگوریتم درخت تصمیم گیری
الگوریتم های درخت تصمیم در یادگیری ماشین، هم برای پیش بینی و هم برای کلاسه بندی استفاده می شوند. با استفاده از درخت تصمیم گیری با مجموعه ای از ورودی های داده شده، می توان نتایج مختلفی بدست آورد که حاصل تصمیم گیری هاست. ما می توانیم درخت های تصمیم گیری را با مثال زیر درک کنیم:
بیایید فرض کنیم که شما باید برای خرید برخی از محصولات به بازار بروید. در ابتدا، شما تعیین می کنید که آیا واقعا به محصول نیاز دارید یا خیر. فرض کنید اگر شامپو تمام کرده باشید، فقط شامپو می خرید. اگر هم شامپو برنداشتید، هوای بیرون را بررسی می کنید و می بینید آیا باران می بارد یا نه. اگر بارانی نباشد، شما خواهید رفت و در غیر این صورت نخواهید رفت. می توانیم این مسئله را به صورت یک درخت تصمیم گیری به شکل زیر تصور کنیم:
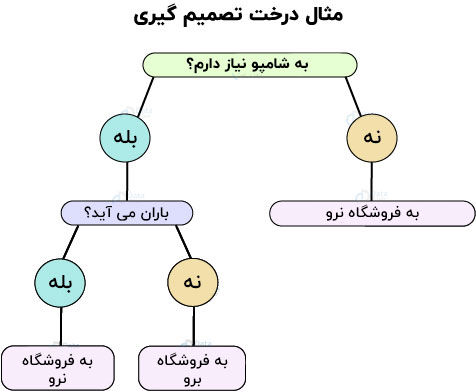
این درخت تصمیم گیری، حاصل مراحل سلسله مراتبی مختلفی است که در تصمیمات خاص به شما کمک می کند. برای ساخت این درخت دو مرحله القا و هرس وجود دارد. در القا، ما یک درخت می سازیم در حالی که در هرس، چندین پیچیدگی درخت را از بین می بریم.
۴- الگوریتم K نزدیک ترین همسایه
K نزدیک ترین همسایه ( K-Nearest Neighbours ) یکی از اساسی ترین و در عین حال از مهم ترین الگوریتم های کلاسه بندی در یادگیری ماشین است. KNN ها متعلق به حوزه یادگیری نظارت شده بوده و کاربرد های مختلفی در شناسایی الگو، داده کاوی و تشخیص نفوذ دارند.
KNN ها، در موارد زندگی روزمره مورد استفاده قرار می گیرند که در آن ها الگوریتم های غیر پارامتری مورد نیاز هستند. این الگوریتم ها، در مورد نحوه توزیع داده ها، هیچ فرضی ندارند. وقتی داده های پیشین داده شد، KNN، مختصات را در گروه هایی که با یک ویژگی خاص شناسایی می شوند، کلاسه بندی می کند.
۵- الگوریتم ماشین بردار پشتیبان
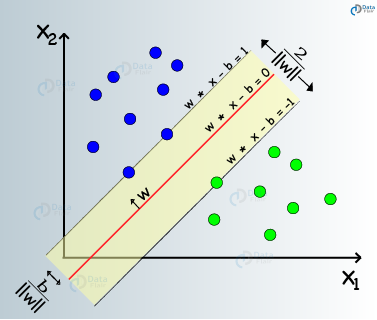
ماشین های بردار پشتیبان نوعی الگوریتم یادگیری ماشین نظارت شده هستند که تحلیل داده ها را برای کلاسه بندی و تحلیل رگرسیون، میسر می سازند. با اینکه SVM ها می توانند برای رگرسیون مورد استفاده قرار گیرند، اما عمدتا برای کلاسه بندی بکار می روند. ما یک ترسیم در فضای n بعدی انجام می دهیم. ارزش هر ویژگی نیز، مختصات مشخص شده می باشد. سپس، ابرصفحه ایده آل را می یابیم تا این دو کلاس را متمایز کند.
این بردارهای پشتیبان، نمایش مختصات مشاهدات تکی هستند. این یک روش مرزی برای جدا کردن دو کلاس است.
با پیاده سازی SVM در پایتون آشنا شوید.
۶- الگوریتم جنگل تصادفی
کلاسه بند های جنگل تصادفی نوعی روش یادگیری گروهی هستند که برای کلاسه بندی ، رگرسیون و سایر کارهایی که با کمک درختان تصمیم گیری انجام می گیرند، استفاده می شود. این درختان تصمیم گیری می توانند در زمان آموزش ساخته شوند و خروجی کلاس می تواند کلاسه بندی یا رگرسیون باشد. با کمک این جنگل های تصادفی، فرد می تواند بیش برازش ( Overfitting ) مجموعه آموزشی را اصلاح کند.
برخی از مزایا و معایب کلاسه بند های جنگلی تصادفی به شرح زیر هستند:
مزایا – کلاسه بند های جنگل تصادفی کاهش بیش برازش ( Overfitting ) مدل را تسهیل می کنند و در برخی موارد دقیق تر از درخت تصمیم گیری هستند.
معایب – جنگل های تصادفی، پیش بینی بلادرنگ ارائه می دهند اما ذاتا کند هستند. پیاده سازی آن ها دشوار است و الگوریتم پیچیده ای نیز دارد.
۷- الگوریتم گرادیان نزولی تصادفی
گرادیان نزولی تصادفی( Stochastic Gradient Descent ) یک کلاس از الگوریتم های یادگیری ماشین است که برای یادگیری مقیاس بزرگ، مناسب است. این روش، نسبت به یادگیری مجزا سازی کلاسه بند های خطی با تابع هزینه محدب که خطی( SVM ) هستند و رگرسیون لجستیک، رویکردی کارآمد است.
ما گرادیان نزولی تصادفی را برای مسائل یادگیری ماشین مقیاس بزرگ که در کلاسه بندی متن و سایر حوزه های پردازش زبان طبیعی وجود دارند، اعمال می کنیم. گرادیان نزولی تصادفی می تواند به طور کارآمد، به مسائلی با بیش از ۱۰۵ نمونه آموزشی حاصل از بیش از ۱۰۵ ویژگی ، بپردازد.
مزایای استفاده از گرادیان نزولی تصادفی:
- این الگوریتم ها بسیار کارآمد هستند.
- می توانیم این الگوریتم ها را به راحتی پیاده سازی کنیم.
با این حال ، گرادیان نزولی تصادفی دارای معایب زیر می باشد:
- الگوریتم گرادیان نزولی تصادفی، به تعدادی ابرپارامتر دارای تنظیم سازی و تعدادی تکرار نیاز دارد.
- همچنین نسبت به مقیاس بندی ویژگی ، که یکی از مهم ترین مراحل پیش پردازش داده ها است ، بسیار حساس است.
۸- الگوریتم تقریبی هسته
در الگوریتم تقریبی هسته ( Kernel Approximation ) ، توابع مختلفی وجود دارند که تقریبی از نگاشت های ویژگی، که مطابق هسته های خاصی هستند و به عنوان نمونه در ماشین های بردار پشتیبان استفاده می شوند، را انجام می دهند. این توابع ویژگی، طیف وسیعی از تبدیلات غیرخطی ورودی را انجام می دهند که به عنوان اساس کلاسه بندی های خطی یا الگوریتم های دیگر عمل می کند.
یک مزیت استفاده از ویژگی های تقریبی که در مقایسه با ترفند هسته، ذاتا واضح هستند، این است که نگاشت های واضح در یادگیری آنلاین بهتر هستند و می تواند در مجموعه داده های بزرگ، به طور قابل توجهی هزینه یادگیری را کاهش دهد. SVM های هسته ای شده استاندارد، نمی توانند به درستی با مجموعه داده های بزرگ مقیاس بندی شوند اما با یک نگاشت تقریبی کرنل می توان از بسیاری از SVM های خطی کارآمد، استفاده کرد.
خلاصه
در مقاله فوق، الگوریتم های مختلفی که برای کلاسه بندی یادگیری ماشین استفاده می شوند را یاد گرفتیم. این الگوریتم ها برای انواع کار ها در کلاسه بندی استفاده می شوند. ما همچنین مزایا و محدودیت های آن ها را مورد بررسی قرار دادیم. هدف از این مقاله تهیه تصویر روشنی از هر یک از الگوریتم های کلاسه بندی در یادگیری ماشین بود.
این مقاله چطور بود ؟ اگر پسندیدید، آن را در شبکه های اجتماعی با دوستان خود به اشتراک بگذارید.
بیشتر بخوانید :
- پلاک خوان های شهر گرینزبوروی آمریکا فعلاً قرار نیست افزایش پیدا کنند
- فرماندار اوکلند از پلاک خوان ها حمایت می کند اما مخالفان در اثربخشی آن تردید دارند
- لبنان استفاده از پلاک خوان های خودکار را تایید کرد
- چالش های مدیریت کلاس با ابزار جدید تشخیص چهره هوش مصنوعی
- آیا می توان از دوربین های ترافیکی برای گرفتن رانندگان الکلی استفاده کرد؟



