
الگوریتم KNN در یادگیری ماشین:
الگوریتم KNN ) K Nearest Neighbor ) یا K نزدیک ترین همسایه که با نام الگوریتم جستجوی مجاورت، جستجوی نزدیکترین نقطه یا جستجوی همسانی نیز شناخته می شود، یکی از ساده ترین الگوریتم های یادگیری ماشین است. این الگوریتم داده های آموزشی را می گیرد و از طریق بررسی عدد K، پاسخ نمونه های جدید را پیش بینی می کند. عدد K از نزدیکترین همسایگی به دست می آید و نمونه های مورد استفاده برای پیش بینی معمولا آراء، محاسبه مجموع وزن دار و … هستند.
مطلب مرتبط :
گاهی اوقات، از الگوریتم K نزدیک ترین همسایه به عنوان روش یادگیری از طریق مثال نیز یاد می شود چرا که برای پیش بینی داده های آموزشی و جدید به دنبال یک ویژگی برداری است که پاسخی شناخته شده به نزدیکترین بردار داده شده را دارد. به زبان ساده تر می توان گفت که نمونه ها در الگوریتم K نزدیک ترین همسایه با استفاده از رای اکثریت همسایه هایش ایجاد می شود. در این حالت K عموما یک مقدار صحیح کوچک و مثبت است.
اگر K=1 باشد، الگوریتم K نزدیک ترین همسایه به سادگی مشخص کننده نمونه جدید است. لازم به ذکر است که در هنگام مشخص کردن نمونه آزمایشی، K با مقادیر فرد بسیار سودمند تر از K با مقادیر زوج است چرا که از مقدار فرد از ایجاد داده های مساوی جلوگیری کرده و به راحتی نتیجه محاسبه را تعیین می کند.
پیاده سازی الگوریتم KNN ، مزایا و معایب آن:
پیاده سازی این الگوریتم یادگیری ماشین بسیار راحت است. الگوریتم K نزدیک ترین همسایه روشی غیرپارامتریک و اثر بخش بوده و از طریق کلاس بندی به پیاده سازی مسائل یادگیری ماشین و غیره می پردازد. این الگوریتم ساده و کاربردی بوده و از طرفی دقت بسیار بالایی دارد. پیاده سازی این الگوریتم جنبه چند منظوره داشته و می توان هم برای طبقه بندی و هم رگرسیون مورد استفاده قرار گیرد. در الگوریتم K نزدیک ترین همسایه مقایسه مدل های یادگیری نیز تحت نظارت بهتر و کامل تری خواهند بود.
اما یکی از ایرادات وارد شده به این الگوریتم، طولانی بودن زمان ارائه نمونه های آموزشی بوده و جستجو برای مقدار بهینه K، اندکی با مشکل مواجه می شود. مشکل دیگری که در این الگوریتم ایجاد می شود نیز زمانی اتفاق میفتد که رای اکثریت (Majority Voting) در توزیع دسته در هم شکسته شود. به این صورت که انتخاب نمونه تصادفی با مشکل مواجه می شود و در بین نزدیکترین همسایه عضو جدید، تعداد زیادی از نمونه ها وجود دارند. البته این مشکل را می توان با روش های گوناگونی مانند وزن دادن به دسته ها اصلاح و برطرف کرد. گران بودن، نیاز به حافظه بالا برای ذخیره تمامی داده های قبلی، احتمال کند بودن مرحله پیش بینی و حساس بودن الگوریتم K نزدیک ترین همسایه نسبت به ویژگی های نامناسب و مقیاس داده اشاره کرد.
تخصیص داده ها اولیه به الگوریتم:
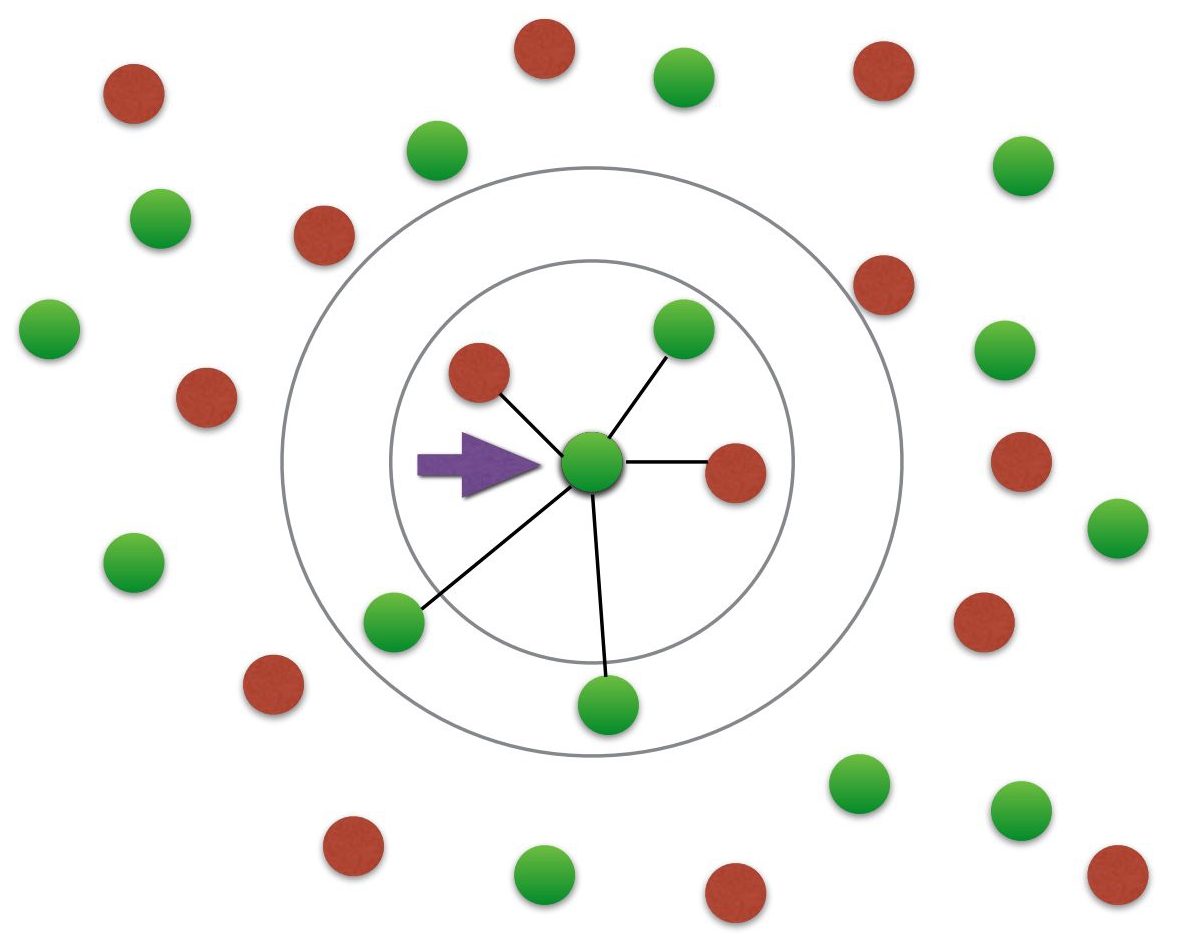
در این الگویتم داده های اولیه هرکدام دارای برچسبی با نام دسته هستند و شامل بردارهایی می شوند که در یک فضای چند بعدی قرار می گیرند. این بردارها همان نمونه های آموزشی هستند که توسط آن ها پارتیشن بندی فضا شکل می گیرد. در این فضا، یک نقطه به کلاسی اختصاص داده می شود که بیشترین نقاط آموزشی مختص آن کلاس موجود است. البته این نقاط آموزشی نزدیکترین همسایگی را با نمونه آموزشی K دارند و نکته بعدی اینکه، در این روش معمولا از تشابه کوسینوسی یا فاصله اقلیدسی استفاده می شود.
فاز یادگیری در الگوریتم K نزدیک ترین همسایه:
در فاز یادگیری (Training Phase) الگوریتم K نزدیک ترین همسایه نیز بردارهای ویژگی ذخیره شده و برچسب دسته ها تعیین و ذخیره می شوند. در این الگوریتم فاصله اقلیدسی معیار فاصله برای متغیرهای پیوسته هستند و در مورد متغیرهای گسسته می توان از معیارهای دیگری مانند فاصله همینگ (Hamming Distance) استفاده کرد.
در روش دیگری برای طبقه بندی در الگویتم K نزدیک ترین همسایه ، نمونه تستی به عنوان برداری در فضای ویژگی نمایش داده می شود و تشابه کوسینوسی و فاصله اقلیدسی با استفاده از تمامی بردارهای آموزشی مورد محاسبه قرار می گیرند و نهایتا نزدیک ترین نمونه آموزشی به K ، انتخاب می شود.
البته برای محاسبه الگوریتم K نزدیک ترین همسایه، روش های گوناگونی وجود دارد اما در روش کلاسیک معمولا براساس بیشترین آراء، نمونه های تستی را انتخاب می کنند. برای این انتخاب، یک مقدار بزرگ K را مورد استفاده قرار می دهند. مزیت نمونه بزرگ K ، دقیق تر بودن آن است چرا که نویز کلی را کم می کند اما برای معتبر بودن آن هیچ تضمینی وجود ندارد. به همین منظور معمولا از اعتبار سنجی متقاطع نیز در الگوریتم K نزدیک ترین همسایه استفاده می شود. (هم چنین می توان گفت که روش اعتبار سنجی متقاطع، روشی مناسب برای اعتبار دادن به مقدار K است). در نهایت می توان در مورد عدد K اعلام داشت که یک K مناسب و معتبر عمدتا عددی مابین ۳ تا ۱۰ است.

فاکتور های مهم در الگوریتم K نزدیک ترین همسایه :
در این الگوریتم یادگیری ماشین، عمدتا سه فاکتور مهم زیر مورد توجه و استفاده قرار می گیرند. این فاکتورها عبارتند از:
- K تعداد همسایه های نزدیک نمونه آموزشی است.
- برای پیدا کردن K نزدیک ترین همسایه، از معیار شباهت یا فاصله استفاده می شود.
- برای شناسایی یک کلاس برای نمونه تستی از K نزدیک ترین همسایه، از قانون تصمیم گیری استفاده می شود.
روش های معمول برای حل مسئه K نزدیک ترین همسایه :
همانطور که قبلا هم اعلام شد، در مورد الگوریتم K نزدیک ترین همسایه راه حل های متعدد و بسیاری پیشنهاد شده است. اما طبق مشاهدات غیر رسمی می توان به این نتیجه رسید که در واقع هیچ راه حل همه جانبه و دقیقی که همیشه به جواب برسد، وجود ندارد و معمولا برای پردازش های چند جمله ای می توان از زمان جستجوی چند لگاریتمی استفاده کرد. اما روش های معمول به صورت زیر هستند:
- جستجوی خطی
- پارتیشن بندی فضا
- درهم سازی مکانی (Hash)
- استفاده از فایل های تقریب بردار
- فشرده سازی / خوشه بندی بر مبنای جستجو
الگوریتم K نزدیک ترین همسایه در OpenCV :
در جلسه بعدی از آموزش یادگیری ماشین OpenCV، الگوریتم K نزدیک ترین همسایه را با استفاده از مثالی ساده که در آن از دو خانواده (کلاس) استفاده می شود، شرح خواهیم داد.
بیشتر بخوانید :
- هوش مصنوعی مولد تهدیدات جدیدی برای امنیت سایبری ایجاد می کند
- فناوری تشخیص پلاک خودرو چگونه جامعه را هوشمندتر می کند
- گوگل ساختار سازمانی خود را جهت تمرکز بر هوش مصنوعی اصلاح می کند
- پلاک خوان های شهر گرینزبوروی آمریکا فعلاً قرار نیست افزایش پیدا کنند
- فرماندار اوکلند از پلاک خوان ها حمایت می کند اما مخالفان در اثربخشی آن تردید دارند



