

مروری بر نحوه توسعه بازی های ویدیویی مبتنی بر هوش مصنوعی به مرور زمان و استفاده های امروزی از آن در بازی ها
اکثر مردم احتمالاً تصور می کنند که اکثر بازی های ویدئویی منتشر شده در چند سال اخیر برای شخصیت ها ، موجودات یا حیوانات کنترل نشده بازی (اغلب در این مقاله به عنوان رباتها گفته می شود) از هوش مصنوعی پیچیده ای استفاده شده است. با این حال ، بسیاری از توسعه دهندگان بازی های ویدئویی در ساخت هوش مصنوعی پیشرفته مردد هستند چرا که واهمهه این را دارند که در بازی هایشان کنترل تجربه کلی گیمر را از دست بدهند. در واقع، هدف هوش مصنوعی در بازی های ویدئویی ایجاد حریفی بی نظیر برای بازیکنان نیست که نتوانند او را شکست دهند، بلکه در عوض به معنای به حداکثر رساندن مشارکت و لذت بردن گیمرها در دوره های طولانی است.
اکثر مردم احتمالاً تصور می کنند که اکثر بازی های منتشر شده در چند سال اخیر برای شخصیت ها ، موجودات یا حیوانات کنترل نشده بازی (اغلب در این مقاله به عنوان رباتها گفته می شود) از هوش مصنوعی پیچیده ای استفاده شده است. با این حال ، بسیاری از توسعه دهندگان بازی های ویدئویی در ساخت هوش مصنوعی پیشرفته مردد هستند چرا که واهمهه این را دارند که در بازی هایشان کنترل تجربه کلی گیمر را از دست بدهند. در واقع، هدف هوش مصنوعی در بازی های ویدئویی ایجاد حریفی بی نظیر برای بازیکنان نیست که نتوانند او را شکست دهند، بلکه در عوض به معنای به حداکثر رساندن مشارکت و لذت بردن گیمرها در دوره های طولانی است.

تاریخچه هوش مصنوعی در بازی ها
هوش مصنوعی یک اصطلاح بسیار گسترده است که لزوماً این گونه نیست که الگویی باشد که از کارهای یک گیمر بیاموزد. بازی ویدئویی سه بعدی Wolfenstein در سال ۱۹۹۲ مجددا روانه بازار شد و حتی سربازان حاضر در آن بازی شکل اولیه ای از هوش مصنوعی را داشتند. الگوریتم حالت محدود ماشین (FSM) یک هوش مصنوعی نسبتاً ساده است که در آن طراحان لیستی از تمام رویدادهای ممکن را ایجاد می کنند که یک ربات می تواند تجربه کند. سپس طراحان پاسخهای مشخصی را که ربات به هر موقعیتی می دهد را به او اختصاص می دهند (لو ، ۲۰۱۷). ما می توانیم تصور کنیم در سال ۱۹۹۲ توسعه دهندگان بازی سه بعدی Wolfenstein تمام موقعیت های ممکن را که یک سرباز دشمن می تواند تجربه کند را در نظر گرفته بودند. دری از نظر آنها می تواند باز شود ، Blazkowicz (قهرمان سری بازی های Wolfenstein )می تواند وارد صحنه شود، آنها می توانند از پشت گلوله بخورند، می توانند رد بلاژوکویچ را گم کنند. توسعه دهندگان این لیست را گردآوری می کنند و برای هر موقعیتی ، به ربات می گویند که باید چه کاری انجام دهد. در اینجا بینشی مفید از مقاله لو (محققی در این زمینه) آورده شده است:
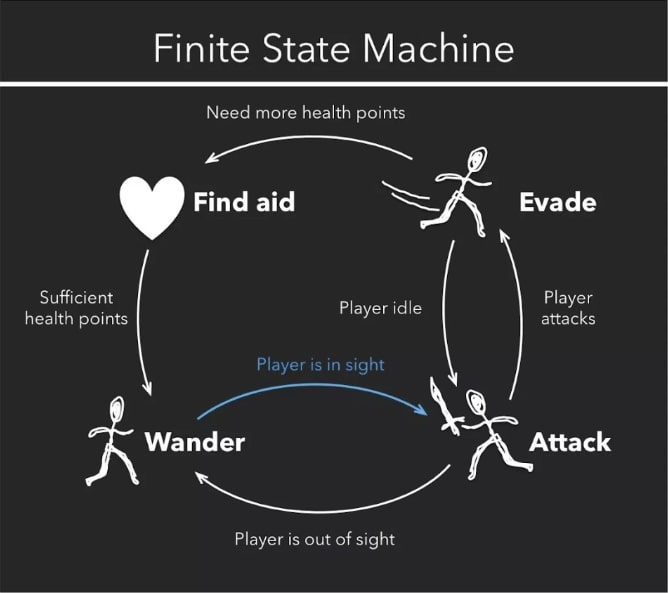
بدیهی است که این (تصویر) نمونه ای بسیار ساده است. ما می توانیم تصور کنیم که با افزودن جزئیات بیشتر در ساخت آن میتوان آن را بسیار پیچیده تر کرد. ربات چه مدت باید در جست و جوی بلاژوکویچ قبل از این که از این کار منصرف شود؟ اگر از یافتن بلاژوکوویچ منصراف شوند آیا باید در همان مکان بمانند یا به نقطه شروع مجدد باز گردند؟ لیست این پرسش ها می تواند به سرعت بسیار طولانی و کاملاً مفصل شود. در FSM، به هر موقعیتی توسط توسعه دهندگان بازی یک اقدام خاص اختصاص می یابد.
الگوریتم FSM برای استفاده در هر بازی امکان پذیر نیست. به عنوان مثال تصور کنید از FSM در یک بازی استراتژی استفاده شود. اگر یک ربات از قبل برنامه ریزی شود تا هر بار به همان روش پاسخ دهد ، بازیکن به سرعت یاد می گیرد که چگونه کامپیوتر را شکست دهد. این یک تجربه تکراری در بازی کردن ایجاد می کند که همانطور که انتظار میرود برای بازیکن خوشایند نخواهد بود. الگوریتم جستجوی درخت مونت کارلو (MCST) برای جلوگیری از قابلیت تکرار پذیری الگوریتم FSM ایجاد شده است. روشی که MCST با آن کار می کند این است که در ابتدا همه حرکات احتمالی که یک ربات در حال حاضر به آن دسترسی دارد را تجسم میکند. سپس، برای هر یک از این حرکتهای ممکن ، تمام حرکاتی را که یک بازیکن می تواند با آن واکنش نشان دهد را تجزیه و تحلیل می کند ، سپس همه حرکت هایی را که آن ربات ممکن است در پاسخ به حرکت های بازیکن نشان بدهد را در نظر میگیرد (لو ، ۲۰۱۷). می توان فهمید که این درخت به سرعت چه اندازه انبوه می شود. در اینجا نمودار خوبی برای تجسم نحوه کار MCST وجود دارد:
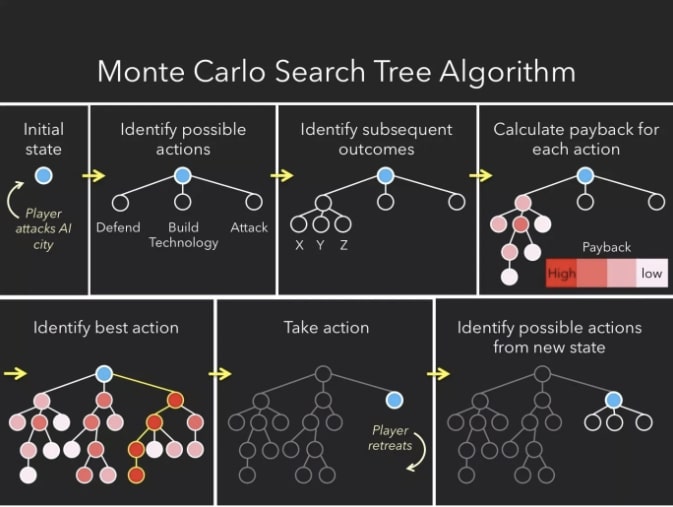
این شکل فرایندی را که یک کامپیوتر با استفاده از MCST قبل از انجام حرکت در برابر یک رقیب انسانی طی میکند را برجسته می کند. در ابتدا همه گزینه های موجود را بررسی میکند، در مثال فوق این گزینه ها یا برای دفاع ، ساخت فناوری یا حمله می باشند. سپس درختی می سازد که احتمال موفقیت هر حرکت بالقوه پس از آن را پیش بینی کند. در بالا می توانیم ببینیم که گزینه با بالاترین احتمال موفقیت “حمله” است (زیرا قرمز تیره برابر است با احتمال بالاتر پاداش و برتری) ، بنابراین کامپیوتر تصمیم به حمله می گیرد. هنگامی که بازیکن حرکت بعدی خود را انجام می دهد ، کامپیوتر دوباره فرایند ساخت درخت را تکرار می کند.
بازی مانند Civilization را تصور کنید که در آن تعداد زیادی از گزینه های رایانه ای وجود دارد که کامپیوتر می تواند انتخاب کند. اگر کامپیوتر بخواهد برای هر انتخاب احتمالی و هر سناریویی که ممکن است برای کل بازی اتفاق بیافتد، یک درخت دقیق بسازد مدت زمان زیادی صرف این کار خواهد شد. در این صورت کامپیوترهرگز حرکت نخواهد کرد. بنابراین ، برای اجتناب از این حجم از محاسبات، الگوریتم MCST به طور تصادفی تعداد معدودی از گزینه های ممکن را انتخاب می کند و درخت تصمیم گیری را فقط برای موارد انتخاب شده می سازد. به این ترتیب ، محاسبات بسیار سریعتر انجام می شود و کامپیوتر می تواند تجزیه و تحلیل کند که کدام گزینه انتخاب شده بیشترین احتمال پاداش و برتری را دارد.
هوش مصنوعی در بازی Alien: انزوا

یکی از اشکال پرطرفدار پیشرفته هوش مصنوعی در بازی های ویدیویی اخیر بازی Alien (بیگانه) محصول کمپانی خلاق Alien : سری Isolation (انزوا) می باشد. برخی سوء تفاهم ها درباره نحوه عملکرد هوش مصنوعی در پشت صحنه وجود دارد. با این حال ، این یک نمایش قابل توجه از راه هایی است که میتوان از هوش مصنوعی برای ایجاد یک محیط جذاب و غیرقابل پیش بینی برای بازیکن استفاده کرد. بیگانه در بازی ویدئویی Alien: Isolation دارای دو نیروی محرک مبتنی بر هوش مصنوعی است که حرکات و رفتارهای خود را کنترل میکند: مدیر مبتنی بر هوش مصنوعی و بیگانه مبتنی بر هوش مصنوعی. مدیر مبتنی بر هوش مصنوعی یک کنترل کننده منفعل است که وظیفه ایجاد تجربه لذت بخش برای بازیکن را بر عهده دارد. برای رسیدن به این هدف ، مدیر مبتنی بر هوش مصنوعی می داند که بازیکن و بیگانه (شخصیت بازی) در کجا هستند. با این حال ، این دانش را با بیگانه به اشتراک نمی گذارد. مدیر مبتنی بر هوش مصنوعی آنچه را که به عنوان معیار اندازه گیری تهدید گفته می شود ، کنترل میکند و این در واقع اندازه گیری میزان استرس مورد انتظار بازیکن است که توسط تعداد زیادی از عوامل مانند نزدیکی بیگانه به بازیکن، میزان زمانی که بیگانه در نزدیکی بازیکن می گذرد ، مقدار زمان صرف شده در برابر بازیکن و مدت زمانی که در دستگاه ردیاب حرکت و غیره قابل مشاهده است، اندازه گیری میشود. این معیار اندازه گیری تهدید و ترس سیستمهای بیگانه را که اساساً فقط یک ردیاب ماموریت برای بیگانگان است ، مطلع می کند. اگرمعیار اندازه گیری تهدید و ترس به سطح مشخصی برسد ، اولویت کار “جستجوی منطقه جدید” است تا زمانی که بیگانه از نزدیکی گیمر به یک منطقه جداگانه حرکت کند تغییر خواهد کرد.
درخت تصمیم گیری رفتار:
قبل از اینکه به این موضوع بپردازیم که چگونه بیگانه مبتنی بر هوش مصنوعی در عمل کار می کند، مهم است که ابتدا ساختارهایی را که به فرایند تصمیم گیری اطلاع می دهند ، برجسته کنیم. بیگانه از یک درخت تصمیم گیری رفتاری گسترده با بیش از ۱۰۰ گره و ۳۰ گره انتخاب کننده استفاده می کند. مثال ساده زیر را تصور کنید:
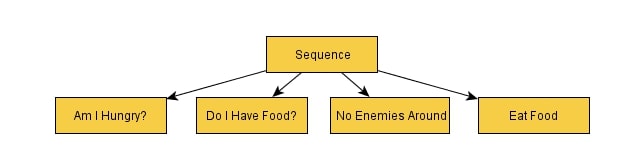
نحوه عملکرد یک درخت رفتار پرسیدن سؤال از چپ به راست است. موفقیت امکان پیشرفت در امتداد درخت را فراهم می کند، در حالی که شکست می تواند شخص را به گره دنباله بازگرداند. در اینجا مراحل آن آورده شده است: آیا من گرسنه هستم؟ (موفقیت) -> دنباله (در حال اجرا) -> آیا غذا دارم؟ (موفقیت) -> دنباله (در حال اجرا) -> دشمنان در اطراف هستند (موفقیت) -> دنباله (در حال اجرا) -> غذا بخورید (موفقیت) -> دنباله (موفقیت) -> گره اصلی (سیمپسون ، ۲۰۱۴). اگر در هر نقطه ، یکی از گره ها با (شکست) مواجه شود، کل دنباله شکست میخورد. به عنوان مثال ، اگر معلوم شد که “آیا غذا دارم؟” رد شده است، بررسی نمی کند که آیا دشمنانی در اطراف وجود دارد و غذا را نمی خورد. در عوض ، دنباله شکست خواهد خورد و این پایان آن دنباله خواهد بود.
توالی ها بدیهی است که بسیار پیچیده تر می شوند و در عمق چند لایه قرار می گیرند. در اینجا مثال عمیق تری آورده شده است:
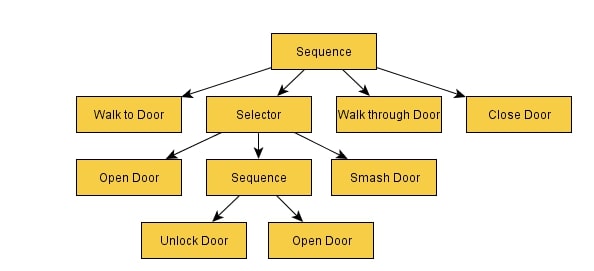
به یاد داشته باشید ، هنگامی که دنباله ای موفق شود یا شکست بخورد ، نتیجه را به گره اصلی باز می گرداند. در مثال بالا، فرض کنیم که ما موفق شده ایم به درب نزدیک شویم ، اما نتوانستیم درب را باز کنیم چون قفل بود و هیچ کلیدی نداشتیم. گره دنباله با شکست مواجه میشود. در نتیجه، مسیر درخت رفتار به گره اصلی (اولیه) آن دنباله باز میگردد. در اینجا ممکن است این گره اولیه به این صورت باشد:
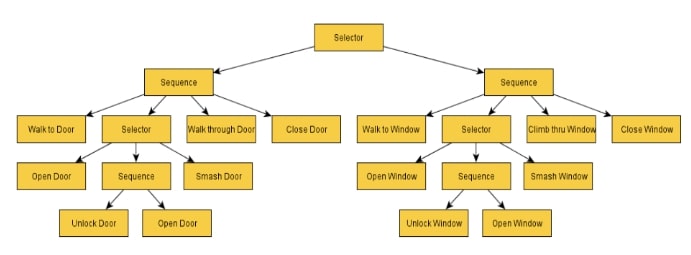
بنابراین ، ما در باز کردن درب شکست خورده ایم ، اما هنوز تسلیم نشده ایم. گره اولیه ما دنباله دیگری برای امتحان کردن دارد. این بار به جای ورود از در از یک پنجره وارد می شویم. شخصیت بیگانه دارای ۳۰ گره انتخاب کننده مختلف و ۱۰۰ گره کلی است ، بنابراین این نمونه از لحاظ ظاهری پیچیده تر است ، اما امیدوارم که این ایده در مورد چگونگی کارکرد شخصیت بیگانه در پشت صحنه که مبتنی بر هوش مصنوعی است به شما ایده دهد.
برگردیم به شخصیت بیگانه مبتنی بر هوش مصنوعی
همانطور که می دانیم ، شخصیت مبتنی بر هوش مصنوعی بیگانه سیستمی است که اقدامات بیگانه را کنترل می کند. هرگز اطلاعاتی درباره مکان بازیکن به او ارائه نمی شود. تنها اطلاعاتی که از مدیر دریافت می کند این است که کدام منطقه را باید جستجو کند. فراتر از آن ، باید بازیکن را به تنهایی پیدا کند. این شخصیت از برخی ابزارها برای کمک به خود در شکار بازیکن استفاده می کند. اولین ابزار سیستم سنسور است که به بیگانه اجازه می دهد تا نشانه های صوتی و تصویری موجود در محیط را دنبال کند. صداهایی از قبیل بالا رفتن از پله ، شلیک گلوله ، باز کردن درها ، حتی بوق زدن ردیاب حرکتی، همه اینها به بیگانه کمک می کند تا بازیکن را ردیابی کند. دامنه صوتی به نوع سر و صدای ایجاد شده بستگی دارد. علاوه بر سنسورهای صوتی، بیگانه همچنین می تواند از حسگرهای تصویری برای تشخسص مواردی چون عبور یک نفر یا باز شدن یک در استفاده کند.
ابزار دیگری که بیگانه برای شکار کردن بازیکن دارد، سیستم جستجو است. مناطق خاصی وجود دارد که توسعه دهندگان آن ها را به عنوان نقاط خوبی برای مخفی شدن تعیین کرده اند و بیگانه را از قبل برنامه ریزی کرده اند تا آن مناطق را جستجو کند. با این حال ، آنها را به هیچ ترتیب خاصی جستجو نمی کند ، و حتی مناطقی را که قبلاً بازدید شده اند مجددا بررسی می کند. البته اگر بیگانه سر و صدایی بشنود یا نشانه ای بصری پیدا کند ، در منطقه ای جستجو می کند که توسعه دهندگان به طور مشخص آن را مشخص نکرده اند. متداول ترین موضوع در مورد Alien: Isolation این است که چگونه بیگانه با پیشرفت بازی اطلاعات بیشتری در مورد بازیکن کسب می کند. به نظر می رسد عملکردهایی که انجام می دهد پیچیده تر است زیرا ویژگی های خاصی راجع به سبک بازی بازیکن می آموزد. چیزی که برای برخی جای تعجب دارد این است که چگونگی دستیابی توسعه دهندگان به این امر با ایجاد یک شبکه عصبی پیچیده در سیستم هوش مصنوعی بیگانه نبوده است. برای نشان دادن این که چگونه بازی حس یادگیری بیگانه را محقق می کند باید به درخت تصمیم رفتاری بیگانه مراجعه کنیم.
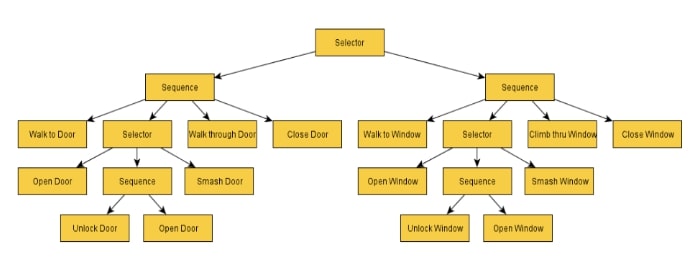
در شروع بازی ، بخش هایی از این درخت رفتاری برای بیگانه مسدود شده است. مناطقی که از بیرون مسدود می شوند ، در دسترس بیگانه نیستند ، به این معنی که نمی توانند به برخی رفتارها و اعمال خاص دسترسی پیدا کند. به عنوان مثال ، در شروع بازی ممکن است بخشی از درخت که به صدای باز شدن درب از فاصله پاسخ می دهد، فعال نباشد. اگر یک بازیکن در منطقه دید بیگانه در را باز کند، می تواند آن بخش از درخت رفتاری را فعال کند، به طوری که در آینده صدای باز شدن درب باعث ایجاد پاسخ خواهد شد. با پیشرفت بازیکن در طول بازی ، درخت رفتاری بیگانه بیشتر و بیشتر فعال می شود. این کار توهم این را که بیگانه در حال یادگیری و سازگاری با سبک بازی بازیکن می باشد را ایجاد میکند.
استفاده از شبکه های عصبی ژنتیکی در بازی های ویدیویی

این مقاله بدون ذکر برخی شبکه های عصبی به کار گرفته شده در بازی های ویدئویی کامل نخواهد بود. نمونه های بسیار مشهور جدیدی وجود دارد که به عنوان مثال در یکی از آنها هوش مصنوعی یک تیم حرفه ای از بازیکنان بازی ویدئویی Dota 2 را شکست داد. با این حال ، بهترین راه برای پوشش این موضوع شروع با گام های کوچک و ایجاد درک اساسی درباره چگونگی یادگیری شبکه عصبی از اهداف و استراتژی های یک بازی ویدیویی است.
بازی ای که برای درک این موضوع استفاده خواهیم کرد Snake است. برای کسانی که ناآشنا هستند با این بازی باید گفت که Snake یک بازی دو بعدی است که در آن شما می توانید یک خط مربع را کنترل کنید ( که به آن مار گفته می شود). شما سه گزینه برای حرکت دارید: چپ ، راست یا مستقیم به جلو. اگر به دیوار برخوردید یا با دم خود برخورد داشتید، فوراً خواهید مرد و مجدداً بازی شروع خواهد شد. یک نقطه برای جمع آوری وجود دارد (به آن غذا گفته می شود) که دم شما با یک مربع رشد می کند. بنابراین هرچه بیشتر بخورید ، بزرگتر می شوید.

بیایید تصور کنیم که می خواهیم به مار خود بیاموزیم که چگونه می تواند بیشترین حد ممکن امتیاز را کسب کند. برای اینکه مار ما در این بازی زنده بماند باید چند نکته را بیاموزیم. به مار خود باید در مورد محیط بازی اطلاعاتی ارائه کنیم. ما به این اطلاعاتی که ارائه می دهیم به عنوان ورودی اشاره خواهیم کرد. این ورودی ها می تواند هر چیزی باشد که ما درباره آنها اطلاعاتی داشته باشیم. به عنوان مثال ، ورودی های ما می تواند شش سوال از نوع بله / خیر باشد: آیا جلو باز است، آیا سمت چپ باز است ، آیا سمت راست باز است ، آیا غذا در جلو وجود دارد؟ آیا غذا در سمت چپ موجود است، آیا غذا در سمت راست وجود دارد (طراحی هوش مصنوعی، 2017). بسته به جواب هر سؤال، ۶ گره ورودی با جواب ۱ یا ۰ را فراهم می شود. با این حال ، این ورودی ها می توانند اندازه گیری فاصله بین سر مار و دیواره یا دم یا غذای آن باشند. برای سادگی ، بگذارید در مثال خود ۶ گره ورودی داشته باشیم.
مورد بعدی که باید به مار آموزش بدهیم همان چیزی است که می خواهیم به آن برسد. برای برقراری ارتباط با هدف مورد نظر خود، سیستم پاداش را پیاده سازی می کنیم. به عنوان مثال ، ممکن است هر بار که ۱ قدم به سمت غذا حرکت می کند به مار خود ۱ امتیاز بدهیم و شاید هر بار که غذا بخورد و طولش رشد کند ۱۰ امتیاز باشد. با این حال ، هنگامی که بینگگزر (طراحی هوش مصنوعی ۲۰۱۷) این پاداش ها را برای مار خود اجرا کرد ، متوجه شد مار او فقط در یک دایره بسیار کوچک حرکت می کند. بدین ترتیب مار وی قادر به جلوگیری از خطرات ناشی از دیوارها و دم بلند بود. بدیهی است ، این نتیجه مد نظر نبود. نیاز به نوعی مجازات وجود دارد که در مدل اولیه وجود داشته باشد و هر زمان که مار از غذا دور شود امتیاز هایش از بین برود. این کار مار را ترغیب به حرکت در جهت غذا کرد.
بنابراین اکنون ما یک مار داریم که اطلاعاتی از محیط و سیستم پاداش دارد که اهداف آن را مشخص می کند. در مرحله بعد چه کار کنیم؟ مار ما چگونه یاد می گیرد که بازی را انجام دهد؟ در این مرحله ، فهمیدن چگونگی عملکرد یک شبکه عصبی سریع می تواند مفید باشد.
شبکه عصبی نسلی
ساختار یک شبکه عصبی نسلی همانند شبکه عصبی استاندارد است. این کار با تعداد معینی از گره های ورودی شروع می شود ، که سپس به یک یا چند لایه پنهان تغذیه می شوند و در نهایت یک خروجی را فراهم می کنند. در اینجا مثال خوبی وجود دارد:
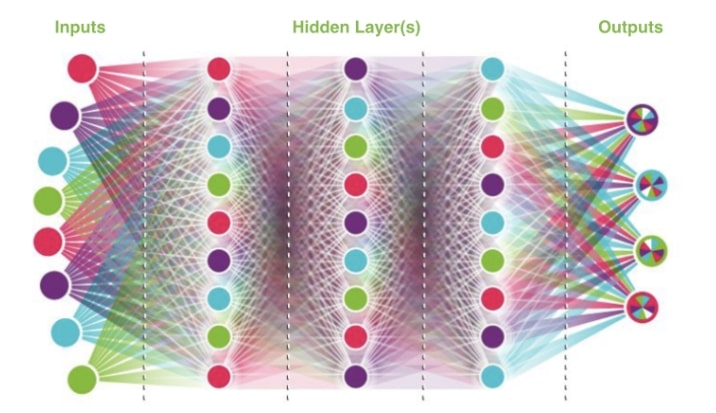
برای مثال برای مار، 6 گره ورودی داریم که ۶ سؤال بله / خیر است که قبلاً تعریف کردیم: آیا مسیر مستقیم باز است ، آیا سمت چپ باز است ، آیا سمت راست باز است، آیا غذا در مسیر مستقیم موجود است ، آیا غذا در سمت چپ موجود است، آیا غذا در سمت راست موجود است. هر گره ورودی از طریق آنچه به عنوان وزن از آنها یاد می کنیم به هر یک از اولین گره های لایه پنهان متصل می شود. در شکل بالا همه خطوط (وزن ها) را که به هر یک از گره ها وصل می شوند، مشاهده میکنید. این وزنها همان چیزی است که الگوی ما باید خود را با آن تنظیم کند ، زیرا یاد می گیرد که کدام ورودی ها قوی ترین یا ضعیف ترین خروجی ها فراهم می کنند. در مثال مورد نظر ما ، “دقیق ترین خروجی” با این عنوان که “مار بیشترین تعداد امتیاز را جمع کند” تعریف شده است. به یاد داشته باشید ، مار ما با حرکت به سمت غذا امتیاز دریافت می کند ، حتی برای خوردن غذا امتیاز بیشتری دریافت می کند و با دور شدن از غذا امتیازات منفی را دریافت می کند.
نحوه یادگیری یک شبکه عصبی نسلی با تصمیم گیری در مورد اندازه هر نسل (اجازه دهید بگوییم که ما می خواهیم هر نسل دارای ۲۰۰ مار باشد) می باشد. در مرحله بعد، ایجاد میکرو تغییر در وزن برای هر یک از ۲۰۰ مار در نسل اول ، سپس هر یک از ۲۰۰ مار در نسل اول فعال میشوند و موفق ترین مار انتخاب می شود (مارهایی که بیشترین امتیاز را کسب کردند). فرض کنیم که ما ۱۰ مار برتر (۵٪ برتر) را داریم که بیشترین امتیاز را در بین مارهای نسل اول کسب کرده اند. این ۱۰ مار سپس “پدر و مادر” نسل دوم می شوند.
از وزن این ۱۰ مار برای تعریف نقطه شروع نسل دوم استفاده می شود. نسل دوم از ۲۰۰ مار موجود دوباره در این وزن ها تغییرات جزئی ایجاد می کنند و نفرات برتر به عنوان “والدین” نسل سوم انتخاب می شوند و این کار به همین منوال ادامه پیدا میکند.
برگردیم به بازی مار خودمان
بنابراین ، همانطور که در بالا دیدیم ، می توانیم مدل مارهای نسل اول خود را بارها و بارها اجرا کنیم (در بالا آن را ۲۰۰ بار آن اجرا کردیم) تا طیف گسترده ای از تغییرات مار را از طریق تغییر جزئی هر یک از وزنه ها ببینیم. سپس نفرات برتر را انتخاب میکنیم که در تأثیرگذاری بر وزن شبکه عصبی در نسل دوم تأثیر گذارند. ما این روند را برای هر نسل بعدی تکرار می کنیم تا زمانی که نرخ یادگیری مار شروع به ترقی کند (به عبارت دیگر ، تا زمانی که پیشرفت نسلی کند یا متوقف شود). شاید در نسل اول ، دوم و سوم هیچکدام از مارها هرگز یک تکه غذا نخورند و بنابراین هرگز یاد نگرفتند که خوردن غذا ۱۰ امتیاز برای آن ها به ارمغان دارد.
با این حال ، شاید در نسل چهارم یک مار یک تکه غذا بخورد. این مار احتمالاً بیشترین امتیاز را در بین مارهای نسل خود خواهد داشت و بنابراین ، برای تأثیرگذاری بر نسلهای آینده انتخاب خواهد شد. وزنهای نسلهای آینده بر اساس موفق ترین مار در نسل های گذشته تغییر می یابد. بعد از ۱۰ ، ۱۰۰ یا حتی ۱۰۰۰ نسل ، می توانید تصور کنید که چه اندازه یادگیری اتفاق خواهد افتاد.
موارد استفاده از بازی های ویدئویی مبتنی بر هوش مصنوعی در دنیای واقعی
همان نوع یادگیری تقویتی که در صنعت بازی های ویدئویی مورد استفاده قرار می گیرد نیز با موفقیت در سایر صنایع به کار گرفته شده است. به عنوان مثال ، بازی های Grand Theft Auto ، که “قوانین راهنمایی و رانندگی ، جاده ها و فیزیک اتومبیل” را به صورت پیش برنامه نویسی در خود دارند (Luzgin، ۲۰۱۸) برای فراهم کردن محیطی ایمن و واقعی برای آزمایش الگوریتم های اتومبیل رانی مورد استفاده واقع است. این کار نه تنها ایمن و واقع بینانه است ، بلکه جمع آوری داده ها در یک محیط مجازی نیز در مقایسه با دنیای واقعی ۱۰۰۰ برابر سریعتر است (Luzgin، ۲۰۱۸).
“بازی های ویدئویی یک روش عالی برای آموزش الگوریتم های هوش مصنوعی است ، زیرا آنها به گونه ای طراحی شده اند که در ذهن انسان پیرفت تدریجی حاصل کنند و به تدریج به چالش های سخت تر و سخت تر بپردازد.” (Luzgin، ۲۰۱۸)
یکی از آخرین پیشرفتهای مرتبط با هوش مصنوعی در بازی های ویدئویی توسط محققان Open AI محقق شده است. Open AI یک بازی مبتنی بر الگوریتمی ایجاد کرد که تنها هدفش کاوش در بازی همراه با حس کنجکاوی طبیعی بود. سیستم پاداش بر روی پاداش دهی بر اکتشافات در صورت پیشروی در بازی متمرکز شده است.
محققان این مدل محور کنجکاوی را در بازی Super Mario Bros قرار دادند و این بازی با موفقیت از ۱۱ سطح از کنجکاوی ناب عبور کرد. بدیهی است که نقاط ضعف زیادی در این امر وجود دارد ، زیرا نیاز به قدرت محاسباتی عظیمی دارد و دستگاه می تواند به راحتی از کار اصلی خود منحرف شود. با این حال، این موضوع برای یک بازیکن انسانی که برای اولین بار این بازی را می کند ، یکسان است. همانطور که لزژین در مقاله خود نقل کرده است ، “به نظر می رسد نوزادان برای یادگیری مهارتهایی که بعداً در زندگی مفید خواهند بود ، از اکتشافات بدون هدف استفاده می کنند.” او معتقد است که اکتشافات بدون هدف در طول زندگی ادامه دار ، اما بارزترین نمونه ی کاوش در محیط های مجازی از طریق بازی های ویدیویی است.
خلاصه مطلب
اشکال زیادی از هوش مصنوعی وجود دارد که در صنعت بازی های ویدیویی امروزی از آن ها استفاده میشود. این که آیا این یک مدل ساده FSM یا یک شبکه عصبی پیشرفته است که از طریق دریافت بازخورد از محیط می آموزد یا نه، امکاناتی که این محیط های مجازی برای پیشرفت هوش مصنوعی ارائه می دهند. (چه در صنعت بازی و چه در خارج از آن) بی پایان است.
بیشتر بخوانید:
- هوش مصنوعی مولد تهدیدات جدیدی برای امنیت سایبری ایجاد می کند
- فناوری تشخیص پلاک خودرو چگونه جامعه را هوشمندتر می کند
- گوگل ساختار سازمانی خود را جهت تمرکز بر هوش مصنوعی اصلاح می کند
- پلاک خوان های شهر گرینزبوروی آمریکا فعلاً قرار نیست افزایش پیدا کنند
- فرماندار اوکلند از پلاک خوان ها حمایت می کند اما مخالفان در اثربخشی آن تردید دارند



