
این مطلب بخش دوم از سری مقاله های آموزشی در مورد چگونگی شروع کار با TensorFlow می باشد که به موضوع متغیر ها در Tensorflow می پردازد.
مقاله مرتبط :

با وجود فراگیر شدن چارچوب های یادگیری عمیق، بسیاری از دانشمندان و محققان داده با معضلی اجتناب ناپذیر روبرو هستند- کدام یک از این چارچوب ها برای پروژه آن ها مناسب است؟
TensorFlow مطمئناً با داشتن گروه های پشتیبانی بزرگ و ‘گرفتن ۱۱۲تا ۱۸۰ ستاره در مخزن GitHub، آن هم در مدت ۳ سال مطلوب ترین کتابخانه برای یادگیری عمیق است.
در اینجا آمار گوگل ترند از TensorFlow در مقابل پیتورچ در ۵ سال گذشته آمده است :
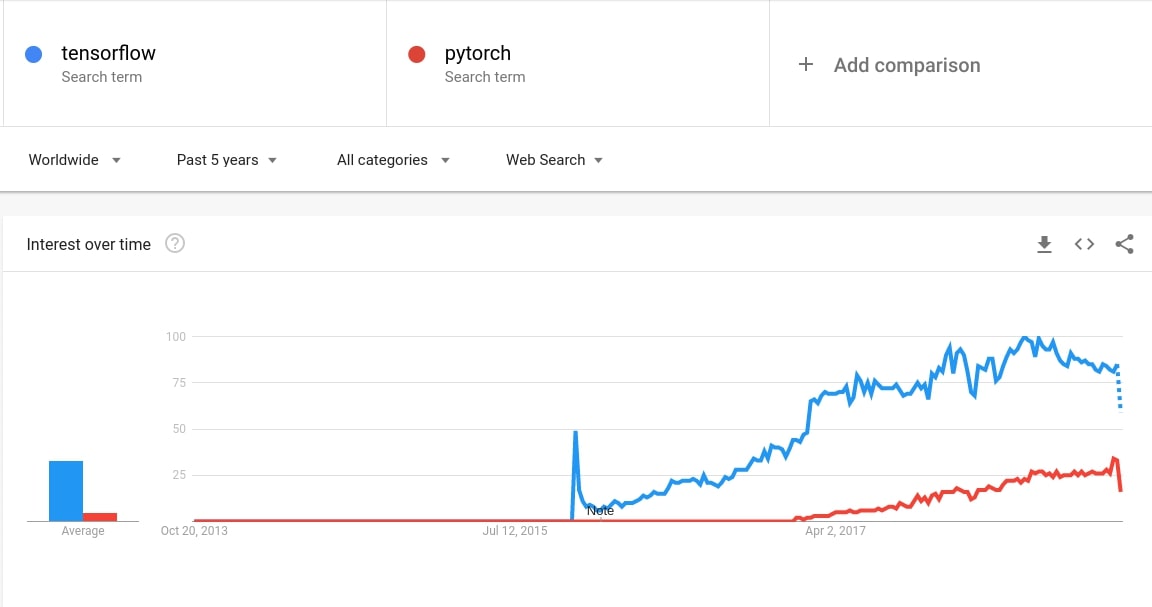
با این حال، میزان پذیرش اولیه TensorFlow توسط جوامع علوم داده به دلیل پایین بودن شیب منحنی یادگیری آن، کم بوده است. هدف از ارائه این مجموعه مقالات این است که یادگیری و استفاده از TensorFlow برای شما آسانتر شود.
در این مقاله (بخش دوم ) مفهوم مهم متغیرها را که به عنوان پایه ساخت مدل عمل می کنند، پوشش خواهیم داد. در پایان این مقاله شما قادر خواهید بود بخش های TensorFlow را با استفاده از متغیرها اعلام و اجرا کنید.
قبل از اینکه در مورد مطالب جدید بحث را آغاز کنیم، بیایید سریع مطالبی را که در مقاله قبلی پوشش دادیم، مرور کنیم:
۱- TensorFlow بر روی نمودارهای محاسباتی که مجموعه ای از گره هاست، کار می کند.
۲- این گره ها به صورت دسته جمعی جریان عملیاتی برای نمودار را تشکیل می دهند.
۳- هر گره، عملیاتی است با برخی از ورودی ها که خروجی لازم را پس از اجرا ارائه می کند.
برای توضیحات بیشتر به مقاله بخش اول: نصب و تنظیم Tensorflow، سینتکس ها و نمودارها مراجعه کنید.
متغیرها
هنگامی که ما یک مدل را معمولاً با روش scikit-learn آموزش می دهیم، وزن ها و بایاس ها با فراخوانی ()model.fit بهینه می شوند. اما در TensorFlow ، شما باید کل مدل یادگیری ماشین را برای خودتان بسازید.
اینجاست که متغیرها وارد صحنه می شوند.
آن ها برای نگهداری مقادیر وزن ها و بایاس هایی که در طی فرآیند آموزش مدل بهینه شده اند، استفاده می شوند. با این حال ، این فرایند با فرآیند فراخوانی سنتی متغیرها متفاوت است.
در TensorFlow ، شما باید قبل از استفاده از آن ها در بخش session، همه متغیرها را تنظیم کنید. بگذارید نمونه ای را بسازیم تا درک بهتری از این مسئله داشته باشیم. ابتدا کتابخانه TensorFlow را وارد کنید و سپس دو متغیر را فراخوانی کنید:
import tensorflow as tffirst_var = tf.random_uniform((4,4),0,1)
second_var = tf.ones((4,4))
print(first_var)Out []: Tensor("random_uniform:0", shape=(4, 4), dtype=float32)
متغیر first_var هنوز یک شیئ در Tensor است و یک آرایه یکنواخت از شکل (۴،۴) نیست.
# Always initialize before running a session init = tf.global_variables_initializer()
به یاد داشته باشید که هنگام طراحی شبکه در TensorFlow، این بلوک کد بسیار مهم است و در عین حال به آسانی فراموش می شود.
with tf.Session() as sess: init.run() print(first_var.eval())Out []: [[0.6423092 0.5614004 0.53549814 0.5330738 ] [۰٫۳۵۲۱۴۸۹ ۰٫۰۷۵۳۷۶۷۵ ۰٫۳۱۸۹۱۴۹ ۰٫۳۸۶۰۶۷۲۷] [۰٫۲۹۵۹۱۶۶۸ ۰٫۳۰۷۳۰۳۶۷ ۰٫۱۷۵۱۱۳۸ ۰٫۷۴۱۷۲۴ ] [۰٫۴۸۲۵۸۷۲۲ ۰٫۳۳۰۹۱۲۹۵ ۰٫۵۷۸۲۶۶۶ ۰٫۷۴۴۷۱۱۵ ]]
بله اولین متغیر شما همین الان مورد ارزیابی واقع شد.
Placeholders (محل ذخیره داده)
همانطور که از نام آن ها پیداست، از آن ها برای نگه داشتن چیزی استفاده می شود. در ارتباط با کار ما، آن ها در ابتدا خالی هستند و مورد استفاده شان در نمونه های آموزشی است که در مدل ها مورد استفاده قرار می گیرند. شما باید در هنگام فراخوانی، نوع داده را تغیین کنید.
integer_placeholder = tf.placeholder(tf.int32) float_placeholder = tf.placeholder(tf.float64)
معمولاً شکل یک placeholder به صورت (None, no_of_features) است. ممکن است برای اولین بار که آن را مشاهده می کنید کمی برایتان گیج کننده باشد. اما در واقع به عنوان مقدار بعدی تعداد نمونه های آموزشی که به مدل خود ارائه می دهیم استفاده از دستور None منطقی به نظر میرسد. مدل ما برای آموزش باید از هر تعداد نمونه ای استفاده کند و این مقدار یک مقدار ثابت نیست.
از طرف دیگر no_of_features یک مقدار شناخته شده است و بنابراین باید متناسب با مدل شما برای مدل شما ارائه شود.
train_data = tf.placeholder(tf.float32, shape=(None,5))
توجه داشته باشید که شکل placeholder برای train_data نیز باید با شکل آن برای test_data یکسان باشد.
test_data = tf.placeholder(tf.float32, shape=(None,5))
چه نوع داده ای را انتخاب کنید؟
تصمیم گیری در مورد داده بسیار مهم است. این مسئله هم می تواند بر زمان آموزش و هم بر روی مدل اثر بگذارد. معمولاً float32 یک نوع داده ایمن هم از نظر عملکرد و هم برای صحت کار محسوب میشود. float64 نیز زمانی که دقت و صحیح بودن از اهمیت بالایی برخوردار باشد گزینه مناسبی است.
اجرای نمودارها و placeholder ها
بیایید با کنار هم قرار دادن مفاهیم نمودارها و placeholder ها، شبکه ساختگی را پیاده سازی کنیم. خواهیم دید که متغیرها نقش مهمی در قسمت بعدی این سری بازی می کنند.
import tensorflow as tf import numpy as np np.random.seed(13) tf.set_random_seed(13)
اگر می خواهید همان خروجی را تولید کنید، عدد تصادفی ۱۳ را برای TensorFlow و numpy اختصاص دهید. بگذارید دو مورد متغیر شماره گیری را ایجاد کنیم که به عنوان نمونه ساختگی و وزن برای مثال ما عمل کنند:
random_data = np.random.uniform(0,100,(5,5)) random_weights = np.random.uniform(0,100,(5,1))print(random_data)[[77.77024106 23.754122 82.42785327 96.5749198 97.26011139] [۴۵٫۳۴۴۹۲۴۷۴ ۶۰٫۹۰۴۲۴۶۲۸ ۷۷٫۵۵۲۶۵۱۴۶ ۶۴٫۱۶۱۳۳۴۴۸ ۷۲٫۲۰۱۸۲۲۹۵] [ ۳٫۵۰۳۶۵۲۴۱ ۲۹٫۸۴۴۹۴۷۰۹ ۵٫۸۵۱۲۴۹۱۹ ۸۵٫۷۰۶۰۹۴۲۶ ۳۷٫۲۸۵۴۰۲۷۹] [۶۷٫۹۸۴۷۹۵۱۶ ۲۵٫۶۲۷۹۹۴۹۳ ۳۴٫۷۵۸۱۲۱۵۲ ۰٫۹۴۱۲۷۷۰۱ ۳۵٫۸۳۳۳۷۸۲۷] [۹۴٫۹۰۹۴۱۸۱۷ ۲۱٫۷۸۹۹۰۰۹۱ ۳۱٫۹۳۹۱۳۶۶۴ ۹۱٫۷۷۷۲۳۸۶ ۳٫۱۹۰۳۶۶۶۴]]print(random_weights)[[ 6.5084537 ] [۶۲٫۹۸۲۸۹۹۹۱] [۸۷٫۳۸۱۳۴۴۳۳] [ ۰٫۸۷۱۵۷۳۲۳] [۷۴٫۶۵۷۷۲۳۷ ]]
توجه داشته باشید که دستور print عمل کرده است زیرا این شیئ ها از نوع شماره گذاری شده (numpy) بوده و از نوع شی Tensor نیستند. در یادگیری ماشین سنتی، وزن ها به طور تصادفی و از طریق theoptimizer بهینه سازی می شوند، ضمن اینکه خطا را با توجه به عملکرد هزینه به حداقل می رساند. در مقاله بعدی مطلب مربوط به آن را نیز پوشش خواهیم داد.
اکنون placeholder ها و عملیاتی که داده های ما را هنگام اجرای session نگه می دارند، کد گذاری کنیم.
a = tf.placeholder(tf.float32) b = tf.placeholder(tf.float32)add_operation = a + b multiply_operation = a * b
خوشبختانه TensorFlow عملیات آرایه ای پیچیده را فقط با عملگر های + ، – ، * و / انجام می دهد.
with tf.Session() as sess:
add_result = sess.run(add_operation,
feed_dict= {a:random_data,
b:random_weights})
mult_result = sess.run(multiply_operation,
feed_dict= {a:random_data,
b:random_weights}) print(add_result)
print('\n')
print(mult_result.round())[[ 84.278694 30.262575 88.93631 103.083374 103.76856 ]
[۱۰۸٫۳۲۷۸۲ ۱۲۳٫۸۸۷۱۴۶ ۱۴۰٫۵۳۵۵۵ ۱۲۷٫۱۴۴۲۲۶ ۱۳۵٫۱۸۴۷۲ ]
[ ۹۰٫۸۸۵ ۱۱۷٫۲۲۶۲۹۵ ۹۳٫۲۳۲۶ ۱۷۳٫۰۸۷۴۳ ۱۲۴٫۶۶۶۷۵ ]
[ ۶۸٫۸۵۶۳۷ ۲۶٫۴۹۹۵۶۷ ۳۵٫۶۲۹۶۹۶ ۱٫۸۱۲۸۵۰۲ ۳۶٫۷۰۴۹۵۲ ]
[۱۶۹٫۵۶۷۱۴ ۹۶٫۴۴۷۶۲۴ ۱۰۶٫۵۹۶۸۶ ۱۶۶٫۴۳۴۹۷ ۷۷٫۸۴۸۰۹ ]]
[[۵٫۰۶۰e+02 1.550e+02 5.360e+02 6.290e+02 6.330e+02]
[۲٫۸۵۶e+03 3.836e+03 4.884e+03 4.041e+03 4.547e+03]
[۳٫۰۶۰e+02 2.608e+03 5.110e+02 7.489e+03 3.258e+03]
[۵٫۹۰۰e+01 2.200e+01 3.000e+01 1.000e+00 3.100e+01]
[۷٫۰۸۶e+03 1.627e+03 2.385e+03 6.852e+03 2.380e+02]]
همانطور که در بالا مشاهده می کنید، عملیات جمع و ضرب با موفقیت انجام شده است. در این اجرا، از متغیرها استفاده نمی شود زیرا ما از هیچ تابع بهینه سازی عملکرد و هزینه استفاده نکرده ایم.
در مقاله بعدی، نحوه کدگذاری یک مثال کامل از رگرسیون خطی در vanilla TensorFlow را شرح خواهیم داد.
بیشتر بخوانید:
- پلاک خوان های شهر گرینزبوروی آمریکا فعلاً قرار نیست افزایش پیدا کنند
- فرماندار اوکلند از پلاک خوان ها حمایت می کند اما مخالفان در اثربخشی آن تردید دارند
- لبنان استفاده از پلاک خوان های خودکار را تایید کرد
- چالش های مدیریت کلاس با ابزار جدید تشخیص چهره هوش مصنوعی
- آیا می توان از دوربین های ترافیکی برای گرفتن رانندگان الکلی استفاده کرد؟



