
این مقاله قسمت سوم از سری مقالات چگونگی شروع کار با TensorFlow می باشد که در این قسمت به بررسی به کار گیری رگرسیون در قالب یک مثال در TensorFlow خواهیم پرداخت.
مقاله مرتبط :

رگرسیون خطی معمولاً همیشه اولین الگوریتمی است که یاد می گیریم. به نظر می رسد که اولین قدم ورود به علم داده باشد! و در حالی که الگوریتم های مؤثرتر دیگر توانسته اند در این زمینه برتری داشته باشند، رگرسیون خطی همچنان جایگاه خود را حفظ کرده است.
یکی از دلایل اصلی که مدل های خطی بطور گسترده به کار گرفته می شوند این است که به راحتی در بستر های مختلف قابلیت استفاده دارند و از نظر محاسباتی سنگین نیستند.
در این بخش قصد داریم الگوریتم رگرسیون خطی را در استفاده از نمودارها ، متغیرها و Placeholder هایی که در دو مطلب آخر آن ها را پوشش داده ایم، پیاده سازی کنیم. اجازه بدهید یک مرور سریع از مطالب گذشته داشته باشیم:
۱- TensorFlow بر روی نمودارهای محاسباتی که مجموعه ای از گره ها را شامل می شوند، کار می کند.
۲- این گره ها به صورت دسته جمعی جریان عملیاتی مورد نیاز برای نمودار را تشکیل می دهند.
۳- هر گره، عملیاتی است با چند ورودی که خروجی مورد نظر را پس از اجرا (Run) فراهم می کند.
۴- متغیرها برای ذخیره کردن وزن ها و بایاس ها مدل آموزش دیده استفاده می شوند در حالی که از Placeholder ها برای ذخیره داده های نمونه ای استفاده می شود.
اگر هر یک از موارد فوق به نظر جدید و ناآشنا می رسد می توانید مقالات قبلی که با موضوعات بالا چاپ شده اند را مطاله کنید.
صورت مسئله:
با وجود ۷۹ متغیر توصیفی (تقریباً) تمام جنبه های خانه های مسکونی در شهر آمس واقع در ایالت آیووا، این مسئله شما را برای پیش بینی قیمت نهایی هر خانه به چالش می کشد.
اکنون با وارد کردن داده ها و کنکاش عمیق در قسمت کدگذاری اجازه دهید کار را شروع کنیم:
import pandas as pd
import numpy as np
import matplotlib as plt
%matplotlib inline
import tensorflow as tf
print("Tensorflow version: {}".format(tf.__version__))train = pd.read_csv("train.csv")
train.head()
از آنجا که هدف ما پیش بینی قیمت فروش خانه ها است، قابل اطمینان ترین متغیر، خود منطقه مورد نظرخواهد بود. حال به بررسی نمودار پراکندگی بین خانه های واقع در منطقه GrLivArea و قیمت آن ها بپردازیم.
train.plot(kind='scatter', x= 'GrLivArea',y ='SalePrice', color='red', figsize=(15,5))
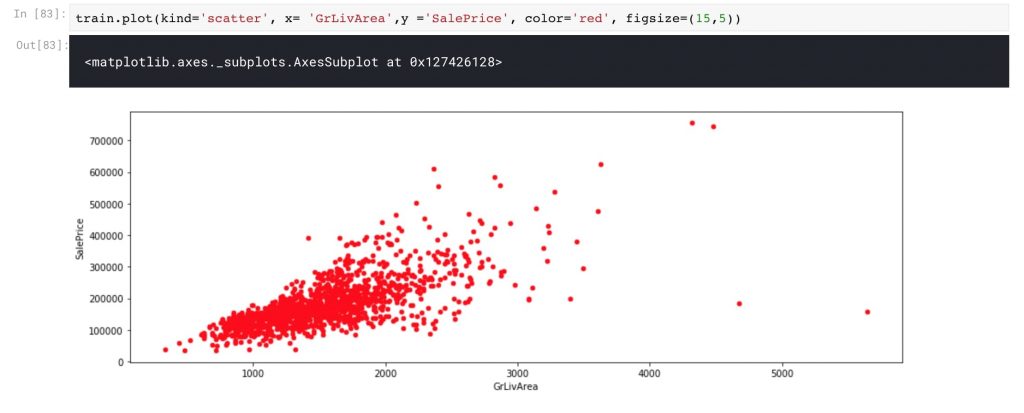
به وضوح می توانیم رابطه خطی بین این دو را ببینیم. اکنون ، بگذارید معادله مدل خطی را بررسی کنیم. y = mx + b ، جایی که m شیب و b عض از مبدا معادله است.
در اینجا ما سعی داریم با استفاده از اطلاعات GrLivArea درستی y_true را پیش بینی کنیم. معادله مدل ما باید به صورت زیر باشد:
قبل از ساختن مدل باید هدف و ویژگی های آن را نیز ارزیابی کنیم.
from sklearn.preprocessing import MinMaxScalerscaler = MinMaxScaler()train_df['GrLivArea'] = scaler.fit_transform(train_df['GrLivArea'].reshape(-1, 1)) train_df['SalePrice'] = scaler.fit_transform(train_df['SalePrice'].reshape(-1, 1))
بالاخره زمان آن رسیده است که مدل را در TensorFlow به صورت کد وارد کنیم! همانطور که قبلاً بحث کردیم ، ضرایب m و b به عنوان متغیر ذخیره می شوند.
# Declaring Variables m = tf.Variable(0.0) b = tf.Variable(0.0) # Declaring placeholders to place the training data xph = tf.placeholder(tf.float32,[batch_size]) yph = tf.placeholder(tf.float32,[batch_size]) # Linear Regression Equation y_model = m*xph + b error = tf.reduce_sum(tf.square(yph-y_model)) # Gradient Descent Optimizer optimizer = tf.train.GradientDescentOptimizer(learning_rate=0.001) train = optimizer.minimize(error)
اسکلت مدل خود را کدگذاری کرده ایم. بگذارید راجع به اجرای گرادیان کاهشی هم بحث کنیم. در TensorFlow ، یک GradientDescentOptimizer داخلی داریم که خطای ما را بهینه می کند. در ارتباط با این مسئله، ما مقدار مربع باقی مانده را کاهش می دهیم:
error = tf.reduce_sum(tf.square(yph-y_model))
train = optimizer.minimize(error)
اکنون بخش مهم آموزش را کدگذاری می کنیم:
# Important! Always initialize the variables
init = tf.global_variables_initializer()
batch_size = 300
with tf.Session() as sess:
sess.run(init)
epochs = 1000
for i in range(epochs):
rand_ind = np.random.randint(len(train_df),size=batch_size)
feed = {xph:train_df['GrLivArea'][rand_ind].values,
yph:train_df['SalePrice'][rand_ind].values}
sess.run(train,feed_dict=feed)
model_m, model_b = sess.run([m,b])
batch_size تعداد داده های نمونه ای است که در یک دوره به کار می روند. پارامترهای batch_size و learning_rate بسته به نوع مسئله می توانند متفاوت باشند.
اکنون مقدار متغیر های m و b را چاپ می کنیم:
print("The trained weight for m is : {m}".format(m=model_m))
print("The trained weight for b is : {b}".format(b=model_b))

وقت آن رسیده که نگاهی به نتایج داشته باشیم! بگذارید این مقادیر را متناسب کنیم و ببینیم y_hat پیش بینی شده چگونه به نظر خواهد رسید.
y_hat = train_df['GrLivArea'] * model_m + model_btrain_df.plot(kind='scatter',x='GrLivArea',y='SalePrice') plt.plot(train_df['GrLivArea'],y_hat,'r')
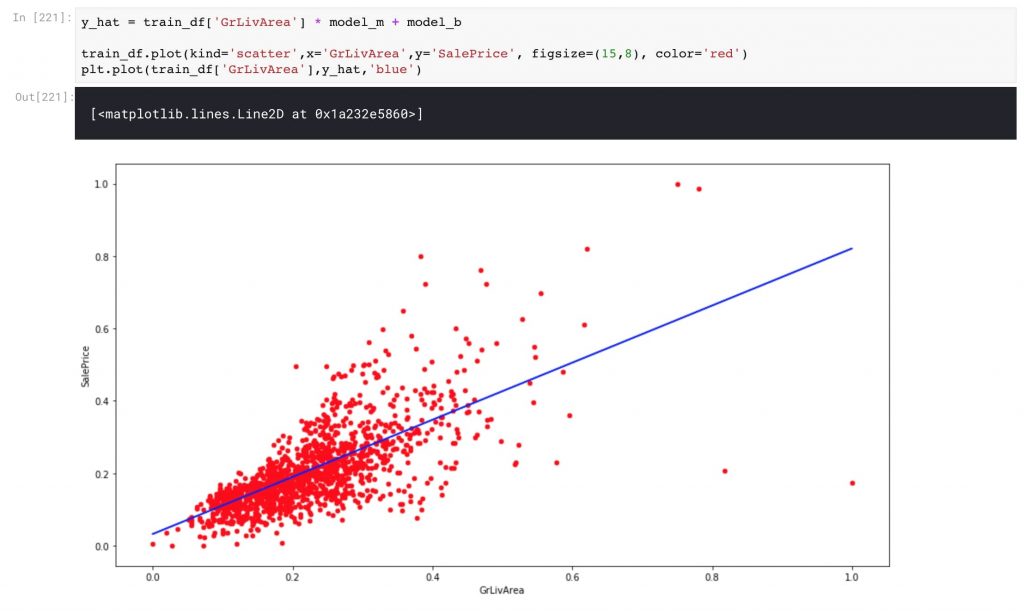
بله مدل ما با استفاده از تنها یک feature، کار خوبی را برای پیش بینی رابطه خطی بین قیمت فروش خانه ها و خانه های منطقه GrLivArea انجام داد. بگذارید همین کار را با بررسی مقدار RMSE (خطای اندازه گیری مربع کامل) تأیید کنیم.
from sklearn.metrics import mean_squared_errorrmse = mean_squared_error(train_df['SalePrice'], y_hat) ** 0.5print("Root Mean Sqaured Error:",rmse )
مقدار RMSE بدست آمده برابر است با :
Out[]: Root Mean Squared Error: 0.07797508645667454
توجه داشته باشید که خطای شما ممکن است متفاوت از مقدار خطای بدست آمده برای ما باشد اما این تفاوت نباید خیلی فاحش باشد. این مقاله در این جا پایان می یابد! و ساخت اولین مدلتان با TensorFlow را تبریک می گوییم!
در مقاله بعدی ، نحوه کدگذاری یک مدل طبقه بندی کامل در TensorFlow را شرح خواهیم داد.
بیشتر بخوانید:
- گوگل ساختار سازمانی خود را جهت تمرکز بر هوش مصنوعی اصلاح می کند
- پلاک خوان های شهر گرینزبوروی آمریکا فعلاً قرار نیست افزایش پیدا کنند
- فرماندار اوکلند از پلاک خوان ها حمایت می کند اما مخالفان در اثربخشی آن تردید دارند
- لبنان استفاده از پلاک خوان های خودکار را تایید کرد
- چالش های مدیریت کلاس با ابزار جدید تشخیص چهره هوش مصنوعی



