
ساختن ویدیو های جعلی از تصاویر بازیگران چیز جدیدی نیست. با این حال، در اواخر سال ۲۰۱۷، یکی از کاربران سایت ردیت به نام Deepfakes شروع به استفاده از یادگیری عمیق برای ساخت ویدیو های جعلی از بازیگران و مشاهیر کرد. این شروع موج جدیدی از انتشار ویدیو های جعلی در اینترنت بود. دارپا ( آژانس پروژههای تحقیقاتی پیشرفتهٔ دفاعی ) نیز همچنین، به عنوان بخشی از ارتش ایالات متحده آمریکا، برای تحقیق در مورد شناسایی ویدیو های جعلی سرمایه گذاری کرده است. در واقع، استفاده از هوش مصنوعی در ساخت ویدیو ها پیش از Deepfakes آغاز شده بود. Face2Face و کلیپ ساخته شده از اوباما ( یادگیری هماهنگی لب ها از طریق صدا ) توسط دانشگاه واشینگتن ( UW ) ویدیو های جعلی ای ساخته بودند که تشخیص آن ها حتی سخت تر از Deepfakes بود. در حقیقت، آن ها به قدری واقعی هستند که Jordan Peele ویدیو زیر را برای هشدار دادن به مردم ساخت.
در این مقاله، ما مفهوم Deepfakes را بررسی می کنیم. برخی مشکلات را شناسایی کرده و روش هایی برای تشخیص ویدیو های جعلی معرفی می کنیم. همچنین به یکی از تحقیقات دانشگاه واشینگتون در زمینه ساخت ویدیو هایی با صدای جعلی نگاهی می اندازیم.
مفهوم پایه:
ایده Deepfake ها بسیار ساده است. فرض کنید میخواهیم چهره ی فرد الف را به ویدیویی با چهره فرد ب تبدیل کنیم.
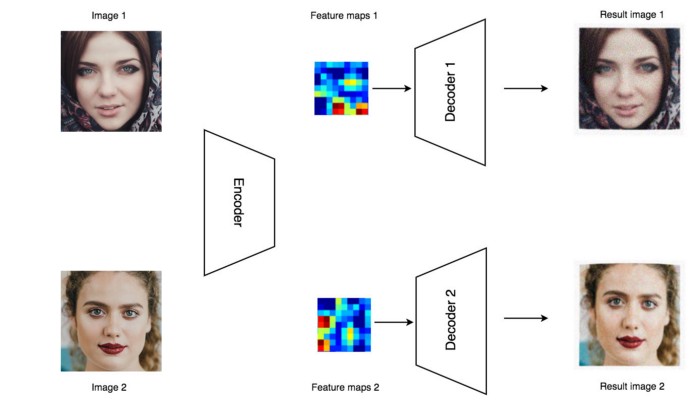
در ابتدا، ما صدها یا هزاران تصویر از این دو فرد را جمع آوری می کنیم. سپس یک رمزنگار ( Encoder ) برای کد کردن این تصاویر با استفاده از یک شبکه عصبی کانولوشنی ( CNN ) مبتنی بر یادگیری عمیق، می سازیم. سپس به وسیله یک رمزگشا ( Decoder ) تصاویر کد شده را به تصاویر واقعی بازسازی می کنیم. این رمزنگار خودکار ( Autoencoder ) که شامل رمزنگار و رمزگشا می شود، میلیون ها پارامتر دارد ولی برای بخاطر سپردن تمام تصاویر اصلا کافی نیست. پس رمزنگار باید برای باز سازی تصاویر ورودی اصلی، ویژگی های مهم را استخراج کند. می توانید این کار را به عنوان طرح یک صحنه جرم تصور کنید. ویژگی ها، توضیحات شاهد هستند ( رمزنگار ) و طراح ( رمزگشا ) از آن شواهد برای باز سازی تصویر مظنون استفاده می کند.
برای دیکود کردن ویژگی ها، ما از رمزگشا های جداگانه برای فرد الف و فرد ب استفاده می کنیم. حال، ما رمزنگار و رمزگشا را (با استفاده از الگوریتم پس انتشار خطا ( Backpropagation )) آموزش می دهیم؛ به گونه ای که ورودی شباهت زیادی به خروجی داشته باشد. این فرایند، زمان بر است. با استفاده از GPUی کارت گرافیک، حدودا ۳ روز طول می کشد تا نتایج قابل قبولی تولید شود ( بعد از ۱۰ میلیون بار پردازش کردن تصاویر ) .
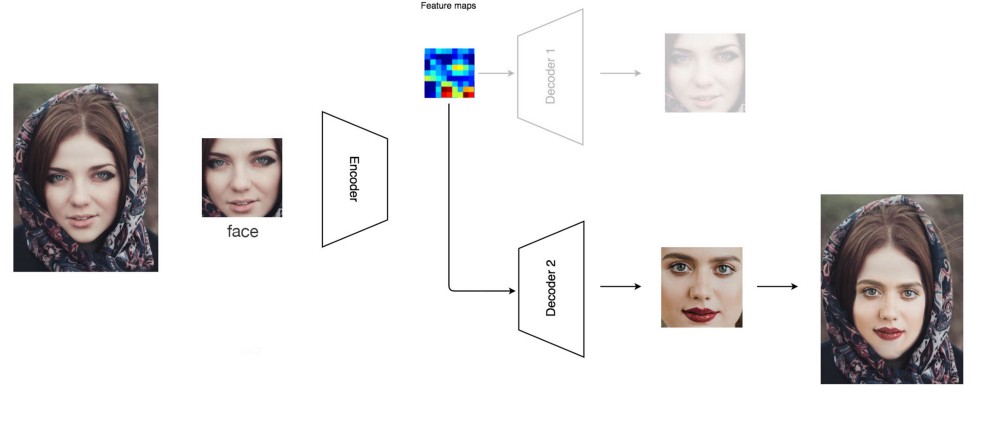
بعد از آموزش، ما ویدیو را فریم به فریم پردازش می کنیم تا تصویر فرد را با دیگری جایگزین کنیم. با استفاده از تشخیص چهره، چهره ی فرد الف را استخراج کرده و آن ر ا به رمزنگار وارد می کنیم. با این حال، بجای استفاده از رمزگشا اصلی برای آن، از رمزگشا فرد ب برای باز سازی تصویر استفاده می کنیم. به عبارت دیگر، ما تصویر فرد ب را با ویژگی های فرد الف در ویدیو اصلی طراحی می کنیم. سپس ما چهره جدید ساخته شده را به تصویر اصلی الحاق می کنیم.
به طور مستقیم، رمزنگار زاویه چهره، رنگ پوست، حالت های چهره، نور و اطلاعات دیگر که برای باز سازی تصویر فرد الف هستند را تشخیص می دهد. وقتی ما از رمزنگار دوم برای بازسازی تصویر استفاده می کنیم، فرد ب را با اطلاعات فرد الف باز سازی می کنیم. در شکل زیر، تصویر باز سازی شده، جزئیات چهره ترامپ را دارد، ولی با نگه داشتن حالات چهره در ویدیوی مبدا.


تصویر :
قبل از آموزش، ما نیاز داریم تا هزاران تصویر از هر دو شخص آماده کنیم. می توانیم یک میانبر بزنیم و از کتابخانه تشخیص چهره استفاده کنیم تا تصاویر چهره را از ویدیو های آن ها استخراج کنیم. زمان قابل ملاحظه ای را صرف بالا بردن کیفیت تصاویرچهره خود کنید. این کار باعث می شود نتایج نهایی بهبود قابل توجهی داشته باشند.
- تصاویری که چهره ی بیش از یک فرد در آن ها وجود دارد را حذف کنید.
- مطمئن شوید ویدیو های فراوان و متفاوتی داشته باشید. تصاویر چهره از ژست های متفاوت، زاویه چهره و حالات محتلف را استخراج کنید.
- هر تصویری با کیفیت بد، رنگ های بهم ریخته، کوچک، نور بد یا تصاویری که چهره در آن ها مشخص نباشد را باید حذف کنید.
- استفاده از تصاویر مشابه از دو فرد، مانند تصاویری با چهره یک شکل، به نتیجه کمک می کند.

ما نمی خواهیم رمزنگار خودکار ما تنها اطلاعات ورودی آموزش را به یاد داشته باشد و مستقیما دیگری را شبیه سازی کند. به یاد داشته باشید تمام احتمالات امکان پذیر نیستند. ما از فرایند های حذف نویز ( Denoising ) برای معرفی انواع داده و آموزش هوشمندانه رمزنگار خودکار استفاده می کنیم. اصطلاح حذف نویز ممکن است گمراه کننده باشد. مفهوم اصلی آن تغییر شکل دادن بعضی اطلاعات است ولی ما انتظار داریم رمزنگار خودکار هوشمندانه بتواند تغییرات غیر طبیعی جزئی را نادیده بگیرد و تصویر اصلی را باز سازی کند. به عبارت دیگر، اجازه می دهد تا اطلاعات مهم را به خاطر بسپارد و متغیر های غیر ضروری را نادیده بگیرد. با تکرار این آموزش در دفعات زیاد، ناهنجاری های اطلاعات یک دیگر را خنثی می کنند و در نهایت از یاد برده می شود. چیزی که باقی می ماند، الگوی اصلی ای است که برای ما اهمیت دارد.
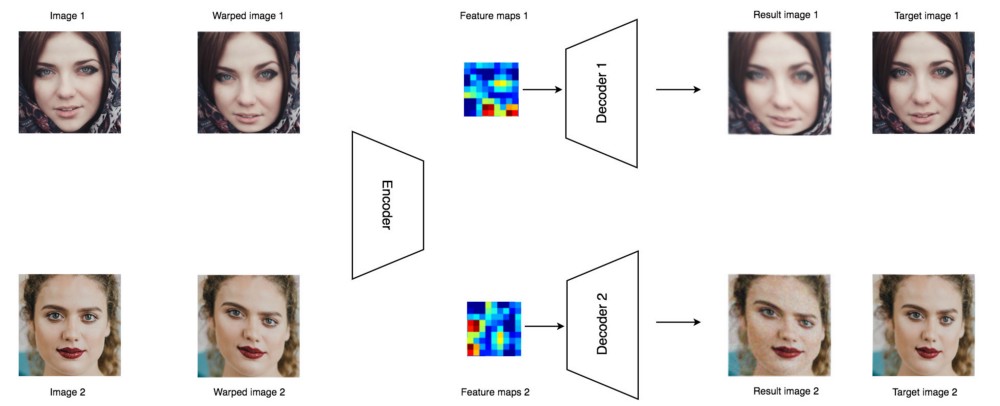
در تصویر چهره ما، یک شبکه ۵*۵ از نقاط را انتخاب کرده و آن ها را اندکی نسبت به مکان آن ها در تصویر اصلی جابجا می کنیم. ما از یک الگوریتم ساده برای اعوجاج تصویر بر مبنای نقاط جابجا شده استفاده می کنیم. حتی تصویر اعوجاج یافته ممکن است درست به نظر نیاید، اما این اختلالی ( Noise ) است که می خواهیم به سیستم معرفی کنیم. سپس ما از یک الگوریتم پیچیده تر برای ساختن تصویر هدف با استفاده از شبکه نقاط جابجا شده استفاده می کنیم. می خواهیم تصاویر ساخته شده تا حد امکان به تصاویر هدف شبیه باشند.

به نظر عجیب می آید ولی این باعث می شود رمزنگار خودکار مجبور شود ویژگی های اصلی را یاد بگیرد.
برای رسیدگی بهتر به ژست های مختلف، زوایا و مکان های چهره، ما همچنین از تقویت تصویر برای غنی سازی اطلاعات آموزش استفاده می کنیم. در طول آموزش، ما تصاویر چهره را در محدوده ی مشخصی به صورت تصادفی چرخش، بزرگنمایی، برگردانی یا تغییر ابعاد می دهیم.
مدل شبکه عمیق
بگذارید یک وقفه کوتاه داشته باشیم تا نشان دهیم رمزنگار خودکار چگونه به نظر می آید. ( برخی اطلاعات اولیه در مورد شبکه عمیق کانولوشنی ( CNN ) در این بخش مورد نیاز است. ) رمزنگار از ۵ لایه کانولوشنی برای استخراج ویژگی ها و ۲ لایه متراکم ساخته شده است. سپس از یک لایه کانولوشنی برای نمونه برداری از تصویر استفاده می کند. رمزگشا ادامه نمونه برداری را با ۴ لایه کانولوشنی یا بیشتر ادامه می دهد تا در نهایت تصویر ۶۴*۶۴ را بازسازی کند.
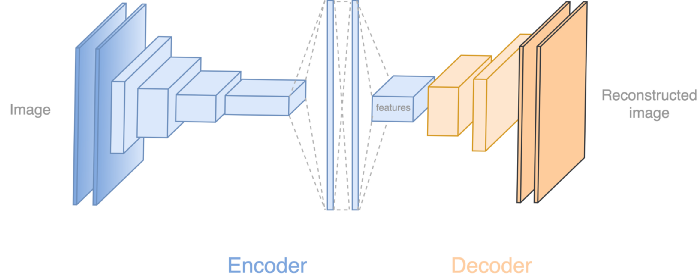
برای نمونه برداری ابعاد فضایی، به عنوان مثال از ۱۶*۱۶ تا ۳۲*۳۲ از یک فیلتر کانولوشنی ( یک فیلتر ۳*۳*۲۵۶*۵۱۲ ) استفاده می کنیم تا لایه (۱۶,۱۶,۲۵۶) را به (۱۶*۱۶*۵۱۲) تبدیل کنیم. سپس آن را به (۳۲,۳۲,۱۲۸) تبدیل می کنیم.
مشکل
بیش از حد هیجان زده نشوید. اگر شما از یک روش پیاده سازی نادرست، تنظیمات نامناسب یا مدلی که به درستی آموزش داده نشده استفاده کنید، نتایج ویدیو زیر را بدست خواهید آورد. ( به چند ثانیه حدود ۳:۳۷ دقت کنید.)
محدوده چهره حالت چشمک زن، محو شدگی با درهم آمیختگی رنگی دارد. و حاشیه های مشخصی در اطراف چهره دیده می شوند. مانند این است که مردم تصاویر را به زور روی چهره او چسبانده اند. اگر نحوه عوض کردن چهره به صورت دستی را توضیح دهیم، این مشکلات به راحتی قابل فهمیدن هستند.
ما با دو تصویر ( تصویر ۱ و ۲ ) از دو زن شروع می کنیم. در تصویر ۴، ما سعی می کنیم چهره ۱ را بر چهره ۲ منطبق کنیم. متوجه می شویم که چهره آن ها بسیار متفاوت است و بریدگی چهره ( مستطیل قرمز ) بسیار بزرگ است. به نظر می رسد کسی ماسک کاغذی بر چهره او گذاشته است. حال، سعی می کنیم چهره ۲ را بر چهره ۱ منطبق کنیم. در تصویر ۳، ما از یک برش کوچک تر استفاده می کنیم. ما یک ماسک ایجاد می کنیم که بعضی از گوشه ها را حذف می کند تا برش ما بهتر بتواند تطبیق پیدا کند. تصویر حاصل بی عیب نیست ولی از تصویر ۴ بهتر است. ولی یک تغییر ناگهانی در رنگ چهره در بخش های مرزی وجود دارد. در تصویر ۵ ، ما وضوح تصویر را در نزدیکی مرز ها کمتر می کنیم تا تصویر تولید شده تطبیق بهتری داشته باشد. ولی نواخت رنگ و روشنایی تصویر برش خورده هنوز هم به تصویر هدف هم خوانی ندارد. پس در تصویر ۶، ما نواخت رنگ و نور تصویر برش خورده را تنظیم می کنیم تا به تصویر هدف شبیه شود. هنوز هم به اندازه کافی خوب نیست ولی برای زحمت کمی که کشیدیم بد نیست.

در DeepFake ها، یک ماسک بر روی چهره تولید شده، ساخته می شود تا آن را با ویدیو هدف تطابق دهد. برای حذف بیشتر ناهماهنگی ها، می توانیم:
- یک فیلتر گرادیان اضافه کنیم تا مرز های ماسک را کاهش دهد،
- برنامه را طوری تنظیم کنیم که ماسک را منقبض یا منبسط کند، یا
- شکل ماسک را کنترل کنیم
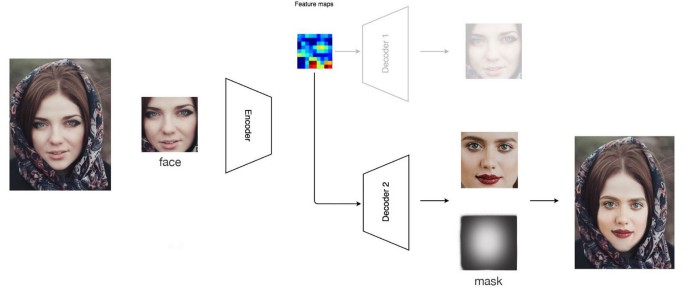
اگر شما به یک ویدیو جعلی دقیق تر نگاه کنید، احتمالا متوجه دوتایی شدن چانه یا لبه های محو خواهید شد. این از عوارض جانبی انطباق دو تصویر روی یک دیگر به وسیله ماسک است. با وجود بهبود کیفیت توسط ماسک، عوارض آن را نیز باید پذیرفت. به طور دقیق، بیشتر ویدیو های جعلی که ما دیده ایم، بخش چهره نسبت به بخش های دیگر تصویر مقداری محو است. برای متعادل کردن آن، ما می توانیمDeepFake ها را طوری تنظیم کنیم که قبل از انطباق به تصاویر چهره فیلتر تیز کنندگی ( Sharpen ) اضافه کند. این یک روش آزمون و خطا است تا بهترین تعادل بین جزعیات و وضوح تصویر را پیدا کنیم. مشخصا، در بیشتر مواقع، ما باید تصاویری با کمی محو شدگی ایجاد کنیم تا جزئیات قابل تشخیص را از بین ببریم.
حتی رمزنگار خودکار نیز برای ایجاد تصاویری که از نظر نواخت رنگ با هدف مطابقت داشته باشند، نیاز به کمک دارد. بیشتر فعالیت Deepfake ها صرف تنظیم رنگ، روشنایی و کنتراست چهره ها برای مطابقت با ویدیو هدف است. همچنین می توانیم از قابلیت شبیه سازی یک پارچه ( Seamless Cloning ) در OpenCV استفاده کنیم تا با استفاده از تنظیم خودکار رنگ، تصویر ساخته شده را با تصویر هدف تطبیق دهیم. با این حال، بعضی از این اقدامات می توانند مخرب باشند. می توانیم یک فریم را بصورت بی نقص و دقیقی بسازیم. ولی با تکرار آن، ممکن است به یک دست بودن موقتی فریم ها آسیب وارد شود. بی شک، شبیه سازی یک پارچه ( Seamless Clone ) در Deepfake ها یکی از اصلی ترین دلیل های پرش و ناهماهنگی تصاویر است. به همین دلیل مردم معمولا شبیه سازی یک پارچه ( Seamless Clone ) را خاموش می کنند تا ببینند پرش های تصویر کمتر می شود یا نه.
یکی دیگر از دلایل مهم در پرش و چشمک زدن تصاویراین است که رمزنگار خودکاردر ساختن چهره های مناسب با شکست مواجه شده است. برای رفع این مشکل، باید از تصاویر متنوع تری استفاده کنیم تا مدل بهبود یابد یا این که از جزئیات بیشتر در داده ها استفاده کنیم. در نهایت، ممکن است نیاز داشته باشیم تا زمان بیشتری را برای آموزش مدل صرف کنیم. در مواردی که نمی توانیم چهره های مناسبی برای بعضی فریم های ویدیو تولید کنیم، آن فریم های مشکل دار را رد ( Skip ) می کنیم و با استفاده از روش های الحاق ( Interpolation ) آن فریم ها را باز سازی می کنیم.
نقاط راهنما
ما همچنین می توانیم با استفاده از نقاط راهنما چهره در تصویر اصلی، روی تصاویر چهره تولید شده اعوجاج ایجاد کنیم.

این روشی است که با استفاده از آن در فیلم یاغی یک ( Rogue One ) چهره پرنسس لیا جوان را روی چهره بازیگر دیگر منطبق کردند.

ماسک های بهتر
در تلاش قبل، ماسک استفاده شده از قبل تنظیم شده بود. اگر از ماسکی استفاده کنیم که به تصویر ورودی و چهره ساخته شده مرتبط باشد، نتیجه بسیار بهتری خواهیم گرفت.
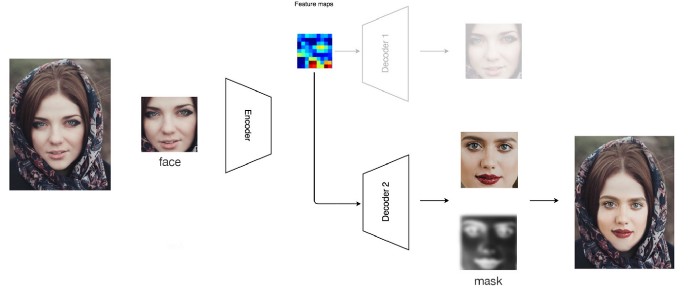
بگذارید شبکه های مولد تخاصمی (Generative Adversary Networks ) را معرفی کنیم.
شبکه های Generative Adversary Networks ) GAN )
در شبکه های مولد تخاصمی ( GAN )، ما یک تفکیک کننده ( Discriminator ) شبکه عمیق ( یک دسته بندی کننده ( Classifier ) شبکه های عصبی کانولوشنی ( CNN ) ) را معرفی می کنیم تا مشخص کند که تصاویر چهره، تصاویر اصلی هستند یا ساخته شده توسط کامپیوتر. وقتی ما تصاویر واقعی را به این تفکیک کننده می دهیم، به تفکیک کننده آموزش می دهیم تا تصاویر واقعی را بهتر شناسایی کند. وقتی ما تصاویر ساخته شده توسط کامپیوتر را به تفکیک کننده بدهیم، از آن جهت آموزش رمزنگار خودکار برای ساختن تصاویر واقعی تر استفاده می کنیم. ما این را به یک پروسه تکرار شونده تبدیل می کنیم تا در نهایت تصاویر ساخته شده از تصاویر اصلی قابل تشخیص نباشند.
اضافه بر آن، رمزگشا ما علاوه بر ماسک ها، تصاویر را هم تولید می کند. چون این ماسک ها توسط اطلاعات آموزش یه سیستم آموخته شده اند، رمزگشا می تواند تصاویر را بهتر ماسک کند و تبدیل ( Transition ) یک نواخت تری برای رسیدن به تصویر هدف ایجاد کند. همچنین، می تواند تصاویر که در ان چیزی در جلو بخشی از چهره قرار گرفته و چهره به طور کامل مشخص نیست را بهتر رسیدگی کند. در بسیاری از ویدیو های جعلی، وقتی بخشی از چهره توسط یک دست مسدود شده، ویدیو ممکن است چشمک زن یا پوشانده شود. با یک ماسک بهتر، می توانیم بخش مسدود تصویر را در چهره ساخته شده ماسک کرده و و آن قسمت را در تصویر هدف استفاده کنیم.
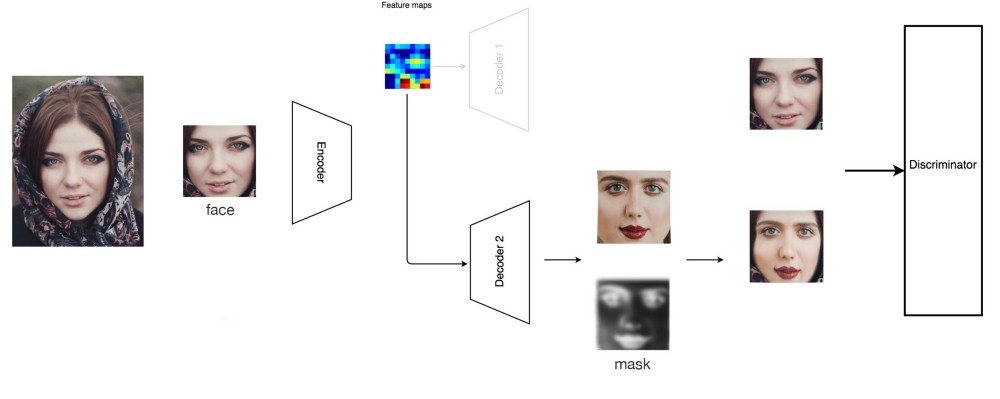
با وجود این که شبکه های مولد تخاصمی ( GAN ) بسیار قدرتمند هستند، مدت زمان زیادی و سطح تخصص بالایی برای راه اندازی درست آن نیاز است. به همین دلیل روش معمولی نیست، با این که باید باشد.
توابع ضرر ( Loss Function )
در کنار هزینه زمانی و پردازشی بازسازی، شبکه مولد تخاصمی ( GAN ) هزینه های تفکیک کننده و سازنده را نیز به آموزش مدل اضافه می کند. در واقع، ما می توانیم توابع ضرر ( Loss Function ) اضافی نیز بار بهبود سیستم به آن اضافه کنیم. یکی از انواع متداول آن، هزینه لبه ها ( Edge Cost ) است که بیانگر این است که آیا تصویر هدف و تصویر ساخته شده لبه های یکسانی در موقعیت یکسان دارند یا نه. همچنین بعضی محققین از خطای ادراکی ( Perceptual Loss ) نیز استفاده می کنند. این تابع خطا، هزینه باز سازی ( Reconstruction Cost ) اختلاف پیکسل ها بین تصویر هدف و تصویر ساخته شده را اندازه گیری می کند. یا این حال، این ممکن است روش ارزیابی خوبی برای این که مغز ما چگونه اشیاء را درک می کند نباشد. به همین دلیل، بعضی مردم ممکن است از ضرر بصری ( Perception Loss ) به جای ضرر باز سازی ( Reconstruction Loss ) استفاده کنند. این روش بسیار پیشرفته است به همین خاطر ما توضیحات این روش را در بخش منابع برای علاقه مندان قرار می دهیم. شما همچنین می توانید ویدیو های خود را برای یافتن مشکلات آنالیز کنید و برای برطرف کردن آن، توابع هزینه ( Cost Function ) جدیدی تعریف کنید.
اظهارات:
بگذارید ما بعضی از ویدیو های جعلی خوب را انتخاب کنیم و ببینم شما می توانید ان ها را تشخیص دهید یا نه. آن ها را با سرعت کم پخش کنید و به دقت به موارد زیر توجه کنید:
- آیا در بخش چهره ها بیشتر از بخش های بدونه چهره ویدیو دچار محو شدگی می شود؟
- آیا چشمک می زند؟
- آیا در رنگ تصویر در کناره های چهره تغییری مشاهده می شود؟
- آیا دچار دوتایی شدن چانه ، دوتایی شدن ابرو ها و دوتایی شدن لبه های چهره می شود؟
- وقتی بخشی از چهره توسط دست ها یا اشیاء دیگر مسدود شده است، آیا تصویر چشمک می زند یا دچار محو شدگی می شود؟
در ساخت ویدیو های جعلی، ما توابع ضرر ( Loss Function ) مختلفی برای جلوه بصری بهتر ویدیو ها استفاده می کنیم. همانطور که در تصاویر جعلی ترامپ مشاهده شد، ویژگی های چهره او به چهره فرد اصلی نزدیک است ولی اگر شباهت چهره بیشتر باشد نتیجه بهتر می شود. از این رو، به نظر ما اگر ویدیو هدف را به دسته بندی کننده ( Classifier ) برای شناسایی بدهیم، احتمال بالایی دارد که با شکست مواجه شود. در ادامه، ما می توانیم برنامه ای بنویسیم که صافی موضعی ( Temporal Smoothness ) بخش های ویدیو را شناسایی کند. چون ما چهره ها را به صورت مستقل در فریم ها به وجود می آوریم، باید توقع داشته باشیم که تبدیل ( Transition ) ها از صافی کمتری نسبت به ویدیو اصلی برخوردار باشد.
هماهنگی لب ها با استفاده از فایل صوتی
ویدیویی که توسط Jordan Peele ساخته شده است یکی از سخت ترین ویدیو ها برای شناسایی جعلی بودن است. ولی وقتی دقیق تر نگاه کنید، لب پایینی اوباما در مقایسه با بقیه بخش های صورتش، محو تر است. به همین خاطر، فکر می کنیم به جای تغییر چهره ی اوباما، از چهره واقعی او استفاده شده ولی دهان او به صورت مصنوعی ساخته شده تا لب های او با صدای جعلی هماهنگ باشد.
برای بخش آخر این بحث، ما میخواهیم در مورد تکنولوژی هماهنگ سازی لب ( Lip Sync ) انجام شده در دانشگاه واشینگتن صحبت کنیم. در پایین، روش انجام عملیات هماهنگ سازی لب ( Lip Sync ) که در گزارش آمده، نشان داده شده. در این روش، صوت یکی از سخنرانی های هفتگی ریاست جمهوری توسط یک صدای دیگر ( صدای ورودی ) جایگزین می شود. در این پروسه، ما لب ها و چانه را طوری بازسازی می کنیم که حرکت آن ها با صدای جعلی هماهنگ باشد.
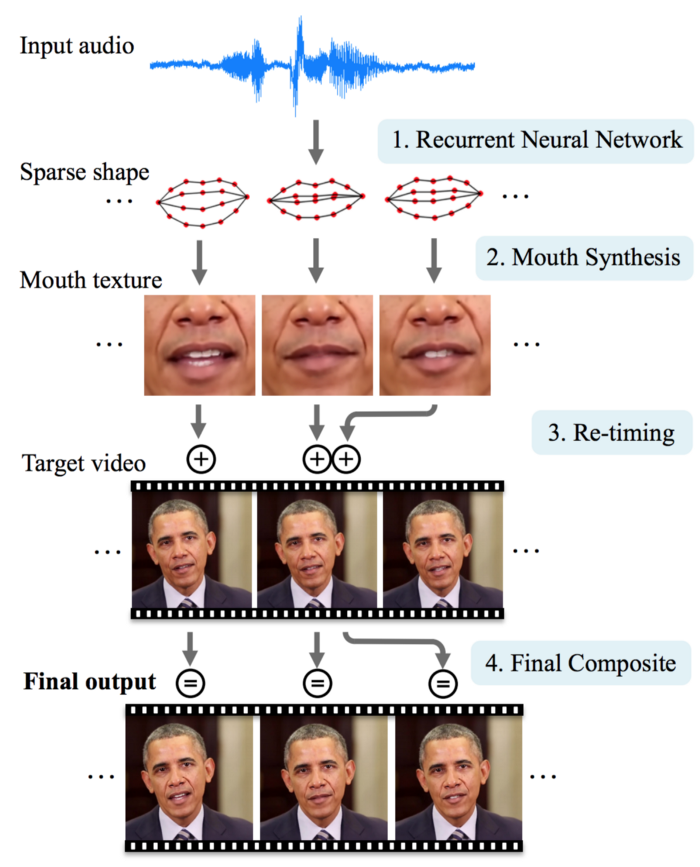
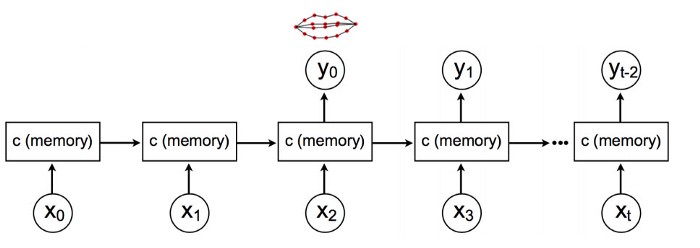
ابتدا، با استفاده از یک شبکه حافظه کوتاه-مدت ماندگار( LSTM ) فایل صوتی X را به ۱۸ بخش از نقاط راهنما Y روی لب ها تبدیل می کنیم. این حافظه کوتاه-مدت ماندگار( LSTM ) فرم گسترده لب ها را برای هر فریم ویدیو به صورت خروجی برمی گرداند.
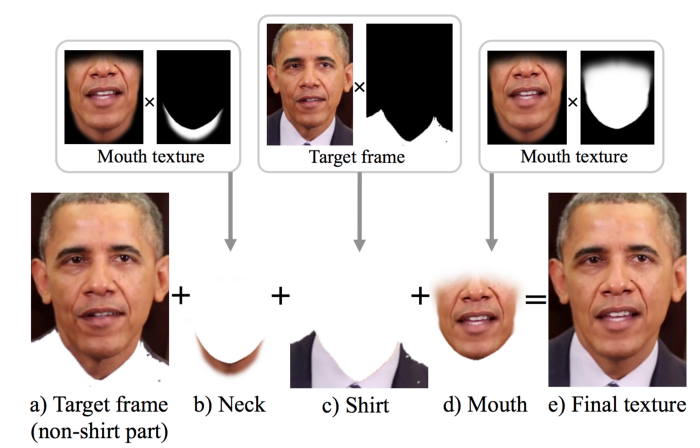
با توجه به فرم لب Y، بافت لب ها و بخش چانه باز سازی می شود. این بافت های دهن در نهایت با در ویدیو هدف قرار می گیرند تا فریم های هدف ساخته شوند.
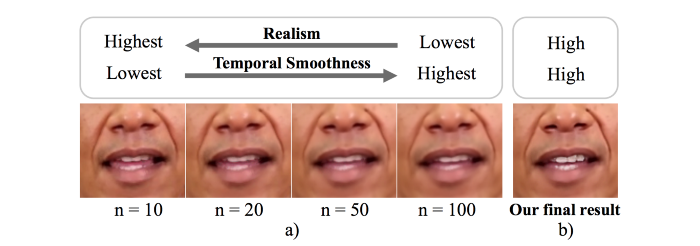
حالا چگونه بافت های دهان را بسازیم؟ ما می خواهیم بافت ها واقعی به نظر برسند ولی یک صافی موضعی ( Temporal Smoothness ) نیز داشته باشند. برای این کار، برنامه به ویدیو هدف نگاه می کند تا فریم های منتخبی را پیدا کند که فرم دهانی محاسبه شده ای مشابه فرمی که ما می خواهیم، داشته باشد. سپس ما فریم های منتخب را با استفاده از یک تابع میانگین ( Median Function ) در کنار هم قرار می دهیم. همانطور که در پایین نشان داده شده است، اگر ما از فریم های منتخب بیشتری برای میانگین گیری استفاده کنیم، تصاویر محو شدگی بیشتری پیدا می کنند و با پیشرفت در صافی موضعی ( Temporal Smoothness ) همراه هستند. از سوی دیگر در صورت استفاده از فریم های منتخب کمتر، تصاویر ممکن است کمتر مخدوش شوند ولی پرش هایی را هنگام گذر از یک فریم به فریم بعدی خواهیم دید.
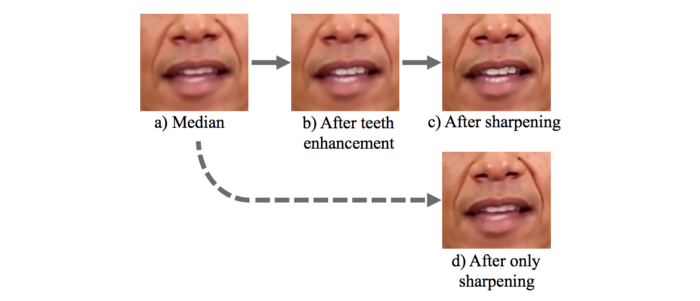
برای جبران محو شدگی، از توابع بهبود دندان ها ( Teeth Enhancement ) و تیز کنندگی ( Sharpening ) استفاده می کنیم. ولی مسلماً، تیزی لب پایینی کاملا قابل بازگشت نیست.
در نهایت، ما زمان بندی فریم ها را مجددا انجام دهیم تا بفهمیم که بافت دهان جعلی را کجا باید قرار دهیم. این به ما کمک می کند تا بتوانیم آن را با حرکت سر هماهنگ کنیم. به طور دقیق تر، سر اوباما معمولا هنگامی که حرف زدنش تمام می شود ثابت می شود.
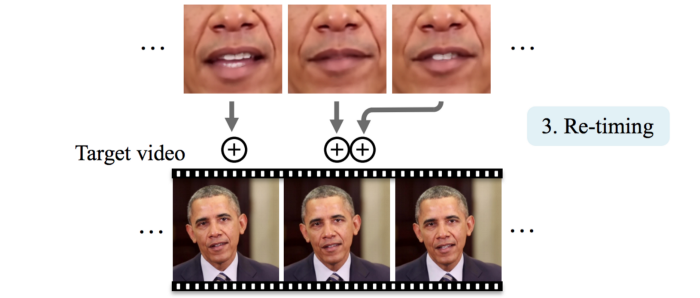
ردیف بالای عکس پایین، فریم های ویدیو واقعی است که صدای آن را به عنوان ورودی استفاده کردیم. ما این صدای ورودی را به ویدیو هدف ( ردیف دوم ) اضافه کردیم. هنگامی که آن را یکی یکی در کنار هم مقایسه کنیم، متوجه می شویم که حرکت لب ها در ویدیو اصلی به حرکت لب ها در ویدیو جعلی بسیار نزدیک است.

دانشگاه واشینگتن از فریم های آماده برای ساختن بافت دهان استفاده کرد. به جای آن، ما می توانیم از ایده Deepfake ها برای ساختن مستقیم بافت های دهان با استفاده از رمزنگار خودکار استفاده کنیم. ما باید هزاران فریم را جمع آوری کنیم و از حافظه کوتاه-مدت ماندگار( LSTM ) برای استخراج ویژگی ها از هر دو فایل ویدیو و صوتی استفاده کنیم. سپس می توانیم رمزگشای برای ساخت بافت دهان آموزش دهیم.
افکار بیشتر
بسیار شگفت انگیز است که ما چگونه از مفاهیم های هوش مصنوعی ( AI ) برای ساختن ایده ها و محصولات جدید استفاده می کنیم، اما بدون اخطار دادن در مورد آن ها! ضربه اجتماعی آن ها می تواند بسیار بزرگ باشد. در واقع، هیچ ویدیو جعلی ای را برای شوخی منتشر نکنید! زیرا می تواند باعث شود شما درگیر مسائل قانونی شده و به وجهه شما در فضای اینترنت ضربه وارد شود. ما این موضوع را به دلیل علاقه مسائل فرا-یادگیری و شناسایی دشمنان و رقیبان دنبال کردیم. بهتر است انرژی خود را برای کار های خلاقانه تر استفاده کنید. از سوی دیگر، ویدیو های جعلی باقی می مانند و پیشرفت می کنند. هدف ما این نیست که ویدیو های جعلی بهتری ساخته شود. از طریق این پروسه، امیدواریم بتوانیم بفهمیم که چگونه از شبکه مولد تخاصمی ( GAN ) برای بازسازی بهتر تصاویر استفاده کنیم. شاید روزی، از آن بتوان برای شناسایی تومر ها کمک گرفت.
به عنوان یک مورد احتیاطی دیگر، مراقب نرم افزار هایی که برای ساخت Deepfake ها دانلود می کنید باشید. گزارشاتی از بعضی نرم افزار ها رسیده که از کامپیوتر ها برای استخراج ارز مجازی استفاده می کنند. فقط مراقب باشید.




از چه منابعی استفاده کردین؟
منبع در انتها مطلب ذکر شده